音频表征与生成的路线之争
把 WavTokenizer 放回整个 audio LM 的脉络里,会发现它只是”编码端”的一个分支。整个 pipeline 分编码和生成两头,每一头都有明显的路线分歧。
编码端:连续 vs 离散
路线 A:连续特征
-
代表:Whisper encoder、HuBERT、WavLM、Wav2Vec 2.0
-
输出是连续向量序列(每帧一个 float 向量),不做量化
-
输入既可以是 waveform(Wav2Vec 直接从原始波形卷积下采样),也可以是 mel(Whisper 先算 mel 再过 conv+transformer)
-
信息保留度高,理解类任务(ASR、音频 QA)几乎都走这条路
-
缺点:没法直接塞进自回归 LM 做”预测下一个”——因为没有离散词表
缺点
路线 B:离散 token(neural codec)
-
代表:EnCodec、SoundStream、DAC、SpeechTokenizer、WavTokenizer
-
Encoder → VQ codebook → Decoder
-
输入一般是 waveform(1D conv 下采样),也有基于 mel 的(更省算力但音质上限略低)
-
信息有量化损失,但能像文本 token 一样被 LLM 自回归建模
-
生成类任务(TTS、音乐生成、S2S 对话)几乎都走这条路
关键观察:同一个系统里两条路线常常并存。 比如 Step-Audio 2 的输入侧用连续 latent 特征(Whisper 风格),输出侧用离散 audio token(CosyVoice 2 tokenizer)。这不是矛盾——“理解”需要高保真信息,“生成”需要离散词表。
生成端:两阶段的”mel 中介”
现代 neural TTS 几乎都是两阶段:
LLM 产出的中间表示
↓ 阶段 1:生成模型 → mel 频谱
↓ 阶段 2:声码器 → 波形阶段 1:token/latent → mel(生成模型的主场)
这一步本质是”欠定的条件生成”——输入的信息量远少于目标 mel,所以需要生成模型补齐细节。主流三选一:
| 方法 | 代表 | 特点 |
|---|---|---|
| Diffusion | Grad-TTS、NaturalSpeech 2 | 音质最好,但几十步采样偏慢 |
| Flow Matching | CosyVoice 2、SEED-TTS、Step-Audio 2 | 训练简单、采样步数少,近两年成为事实标准 |
| 纯回归/GAN | 早期 Tacotron、FastSpeech | 速度快但 mel 偏糊,已基本淘汰 |
Diffusion 和 Flow Matching 在这里是同一思路(学噪声→真实的条件变换),FM 可以理解为走直线的 diffusion。
阶段 2:mel → 波形(声码器)
这一步是确定性映射(mel 是波形的有损表示,缺的主要是相位),解法分两派:
-
神经声码器:HiFi-GAN、BigVGAN、UnivNet
-
转置卷积上采样 + 多尺度 GAN 判别器
-
一次前向,ms 级延迟,音质接近真人
-
现在 LALM 几乎都用这一路(Step-Audio 2、CosyVoice、Kimi-Audio)
-
-
基于信号处理的声码器:iSTFT、Griffin-Lim、Vocos
-
直接用逆短时傅里叶变换, 比神经网络更快
-
Vocos 是近期代表:让网络预测 STFT 的幅度+相位,再用 iSTFT 还原——把神经网络的表达力和 FFT 的速度结合起来,比 HiFi-GAN 快约 10 倍
-
纯 Griffin-Lim 不学相位,靠迭代估计,音质差,现在基本只做 baseline
-
为什么阶段 2 还在用 GAN 而不是 diffusion? 因为 mel→波形是信息量上采样而非欠定生成,不需要多步去噪;GAN 一次前向就够,部署成本低得多。实时语音对话受不了几十步采样的延迟。
一张表看整个谱系
| 系统 | 输入侧编码 | 输出侧生成(阶段 1) | 输出侧声码器(阶段 2) |
|---|---|---|---|
| Whisper | 连续 mel latent | — | — |
| HuBERT/WavLM | 连续 waveform latent | — | — |
| EnCodec/DAC | 离散 RVQ token | — | codec decoder(内建) |
| WavTokenizer | 离散单层 VQ token | — | codec decoder(内建) |
| CosyVoice 2 | 离散语义 token | Flow Matching → mel | HiFi-GAN |
| Step-Audio 2 | 连续 latent + 离散 token | Flow Matching → mel | HiFi-GAN |
| Vocos 系方案 | — | 任选 | iSTFT + 网络预测相位 |
Motivation
共同范式
论文 Introduction 引用的这些工作都遵循同一个核心思路:
文本/prompt → LLM(自回归 Transformer)→ 离散 audio token → Codec Decoder → 波形它们都依赖 neural codec(EnCodec / SoundStream / DAC)把连续音频变成离散 token,然后用语言模型的方式去“预测下一个 token”来生成音频。本质上是把音频当作一种“外语”,用 NLP 的方法来“说话”。
代表性工作
| 工作 | 任务 | 核心做法 |
|---|---|---|
| VALL-E (Wang et al., 2023) | 多说话人语音合成 | AR 生成第 1 层 codec token(粗轮廓),NAR 并行生成 2-8 层(补细节)。3 秒参考音频即可克隆说话人。开创了“语音即语言建模”的范式 |
| SPEAR-TTS (Kharitonov et al., 2023) | 语音合成/克隆 | 两阶段:先生成语义 token(自监督模型),再生成声学 token。语义→声学的转换实现了语音克隆 |
| MegaTTS (Jiang et al., 2023, 2024) | 零样本语音合成 | 把语音拆解为内容、韵律、音色等解耦表征,用 LM 对韵律建模。蒋子越(纪升鹏同组学长)的工作 |
| Language-Codec (Ji et al., 2024c) | Codec + 下游合成 | 纪升鹏的前置工作。设计 MCRVQ 把信息均匀分布到各层 quantizer,4 层即够用 |
| MusicLM (Agostinelli et al., 2023) | 文本→音乐生成 | Google。多层语义+声学 token 层级生成,先粗后细 |
| AudioGen (Kreuk et al., 2022) | 文本→音效/环境声 | Meta。用 EnCodec token 作为目标,训自回归 Transformer 生成 |
WavTokenizer 的定位
这些工作都依赖 codec 来产生离散 token,但现有 codec 存在两个问题:
-
token 太多:DAC 需要 900 token/秒,LM 生成效率低
-
语义不足:codec token 主要编码声学信息,缺乏 ASR 级别的语义理解
WavTokenizer 就是解决 codec 这个环节——让 token 更少(75/秒)、语义更丰富、单层量化器可直接接入 LLM,不需要复杂的多层生成架构。
原始音频的采样
什么是采样
麦克风录音的本质:每隔固定时间,测量一次空气振动的幅度,记录为一个浮点数。
采样率(Sampling Rate) 在**录音/录像的那一刻就被写死了,**决定了每秒采样多少次:
- 采样率 = 24,000 Hz(24 kHz)→ 每秒 24,000 个浮点数
audio = [0.012, -0.003, 0.027, 0.051, -0.044, ...] # 共 24,000 个数/秒常见采样率
| 采样率 | 每秒浮点数 | 常见用途 |
|---|---|---|
| 8 kHz | 8,000 | 电话语音 |
| 16 kHz | 16,000 | 语音模型(HuBERT、Whisper) |
| 24 kHz | 24,000 | WavTokenizer、EnCodec |
| 44.1 kHz | 44,100 | CD 音质、音乐 |
| 48 kHz | 48,000 | 专业音频、视频配音 |
奈奎斯特定理
采样率决定了能表示的最高频率:最高频率 = 采样率 / 2
-
24 kHz 采样 → 最高表示 12 kHz → 覆盖人声足够
-
44.1 kHz → 最高 22.05 kHz → 覆盖人耳听觉上限(~20 kHz)
WavTokenizer 选 24 kHz 是平衡点:对语音和一般音频够用,同时比 44.1 kHz 少了近一半的数据量。
WavTokenizer 的压缩有多猛
原始:24,000 个浮点数/秒 × 32bit = 768 kbps
↓ WavTokenizer
压缩后:75 个 token ID/秒 × 12bit = 0.9 kbps
实际压缩比 ≈ 853 倍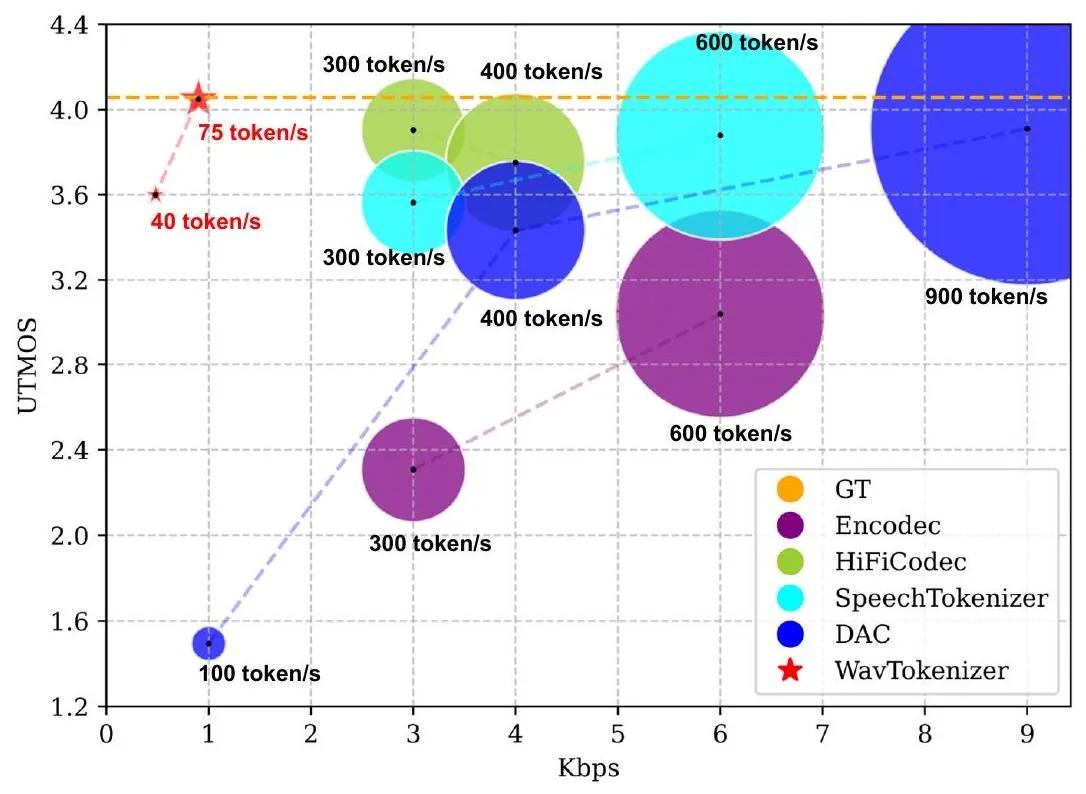
Single Quantizer vs. Multiple Quantizers (RVQ)
传统做法:RVQ(残差向量量化)— 多层量化器
以 DAC 为例,用 9 个量化器串联工作:
Encoder输出 (连续向量)
↓
第1层量化器 → 找最近的 codebook 向量 → 得到 token₁ + 残差₁
↓
第2层量化器 → 对残差₁再量化 → 得到 token₂ + 残差₂
↓
第3层量化器 → 对残差₂再量化 → 得到 token₃ + 残差₃
↓
...重复 9 次...每个时间步产生 9 个 token(每层一个),逐步精修:
-
第 1 层:粗略轮廓
-
第 2-9 层:逐步补充细节
所以 DAC 一秒需要 100 帧 × 9 层 = 900 个 token。
WavTokenizer 的做法:Single Quantizer — 单层量化器
Encoder输出 (连续向量)
↓
唯一的量化器 → 找最近的 codebook 向量 → 得到 1 个 token,结束每个时间步只产生 1 个 token,一秒就是 75 个 token。
为什么 Single Quantizer 重要?
| 多层量化器 (RVQ) | 单层量化器 | |
|---|---|---|
| 每帧 token 数 | N 个(N = 量化器层数) | 1 个 |
| 下游 LM 建模 | 需要特殊设计(AR+NAR、并行生成等) | 直接当普通 token 序列,自回归即可 |
| 接入多模态 LLM | 复杂,要处理多层 token 关系 | 无缝接入,和文本 token 一样串起来 |
核心意义:单层量化器让语音可以像文本一样被当作一维 token 序列,直接丢进 LLaMA 这样的自回归模型,不需要任何额外架构设计。这对做 GPT-4o 那样的统一多模态模型至关重要。
代价与解决
代价:一个量化器要承担原来多个量化器的信息量。
解决:把 codebook 从 (1024)扩到 (4096),用更大的”词汇表”弥补层数的减少。配合 K-means 初始化和 dead code 替换策略来保证 codebook 利用率。
WavTokenizer 的三件套网络结构
整个模型沿用 VQ-GAN 的 Encoder → VQ → Decoder 三段式,训练端再加一组 discriminator 做感知损失。真正值得看的是 decoder,encoder 和 discriminator 基本是前人工作的继承。
Encoder(3.1)
基本照抄 EnCodec
结构流水线:
1D conv (C=32, k=7)
↓
4 × ConvBlock 每块 = [residual unit (两个 k=3 conv + skip)] + [strided conv 下采样]
channel 每次下采样翻倍
↓
2 层 LSTM 做序列建模
↓
1D conv (D=512, k=7) 输出 512 维 latent激活函数用 ELU。唯一可调的是 stride 组合,它决定了最终 token 率:
24khz
| stride | 总下采样 | token/s | bitrate (12 bit/token) |
|---|---|---|---|
| (2, 4, 5, 8) | 320× | 75 | 0.9 kbps |
| (4, 5, 5, 6) | 600× | 40 | 0.48 kbps |
立场: encoder 没有创新,和 EnCodec 几乎一模一样。论文的真正贡献集中在 decoder 和 codebook 设计。
Decoder(3.3)—— 真正的重点
为什么不用镜像上采样
传统 codec(DAC/EnCodec)的 decoder 是 encoder 的镜像:一堆转置卷积把 feature 沿时间维度逐级上采样回波形。问题是转置卷积容易产生 aliasing artifacts(混叠伪影,听感上像金属声或颤音)。
WavTokenizer 跟 Vocos 学:全程不做时间维度上采样,feature resolution 从头到尾保持在 75 Hz,最后一步用 iSTFT 把频域直接变回时域波形。
iSTFT 是确定性的信号处理操作,不会引入伪影。
数据流
Z_q (75 × 512)
↓ Conv1D
↓ Attention block ← 放在 ConvNeXt 之前
↓ ConvNeXt blocks ← 主干
↓ 线性投影到 (n_fft + 2) 通道
↓ 拆成 幅度 + 相位
↓ iSTFT
波形 (24000 样本/秒)ConvNeXt Block 的结构:大核 depthwise conv → pointwise conv 升维 → GELU → pointwise conv 降维,块间用 LayerNorm。本质就是 Transformer-style 的卷积块。
两个关键设计决定
① Attention 只放 decoder、且 ConvNeXt 之前
论文做了全排列消融,结论:放 encoder 没用、放 decoder 的 ConvNeXt 之后也不如放之前。直觉是——decoder 需要从高度压缩的 Z_q 重建出丰富细节,attention 在最前面能先做全局信息聚合,再交给 ConvNeXt 做局部精修。
② 训练窗口 1s → 3s
| 窗口 | UTMOS | PESQ | STOI |
|---|---|---|---|
| 1 秒 | 3.74 | 2.01 | 0.894 |
| 3 秒 | 4.05 | 2.37 | 0.914 |
| 5 秒 | 4.04 | 2.36 | 0.913 |
直觉:1 秒 clip 常常撞到静音,attention 吃不到足够语义;3 秒刚好让 attention 捕捉到词一级的上下文;5 秒边际收益几乎为零。
Discriminator & Loss(3.4)
三套 discriminator 并用
| 名字 | 看什么 | 来源 |
|---|---|---|
| MPD (multi-period) | 波形的时域周期性(按不同周期 reshape 后看二维图案) | HiFi-GAN |
| MRD (multi-resolution) | 多分辨率频谱,分单带幅度 + 多带复数两条路 | UnivNet |
| MS-STFT | 多时间尺度的复数 STFT,按子带切分提供更强梯度信号 | EnCodec / DAC |
Hinge loss 而不是 LS-GAN。
Generator 四项损失
| Loss | 形式 | 作用 |
|---|---|---|
| Quantizer | $\ | Z - \hat{Z}\ |
| Mel | $\ | \text{Mel}(X) - \text{Mel}(\tilde{X})\ |
| Adversarial (hinge) | 各 D 求平均 | 逼真度 |
| Feature matching | 各 D 中间层特征的 L1 | 稳定对抗训练 |
总 loss 是四项加权和,权重是超参。
消融排序(Table 6,LibriTTS-only 585h)
| 去掉什么 | UTMOS 下降 |
|---|---|
| 换回镜像 decoder | −1.27(最致命) |
| 去掉 attention 模块 | −0.45 |
| 去掉 MS-STFT discriminator | −0.27 |
立场: 重要性排序很清楚,decoder 结构 ≫ attention ≫ MS-STFT。discriminator 组合和四项 loss 的配方几乎是 EnCodec/DAC 的照搬,不是 WavTokenizer 的贡献点;真正让它和竞品拉开差距的是 iSTFT decoder + attention + 大 codebook 这三件事
Codebook 训练流程
论文 Section 3.2 对 K-means 初始化的描述有歧义(“adjust the number of cluster centers to 200”),对照 GitHub 开源实现 后,实际流程如下:
配置参数
vq_bins: 4096 # codebook 大小(离散 token 总数)
vq_kmeans: 200 # K-means 初始化的迭代轮数(不是聚类中心数)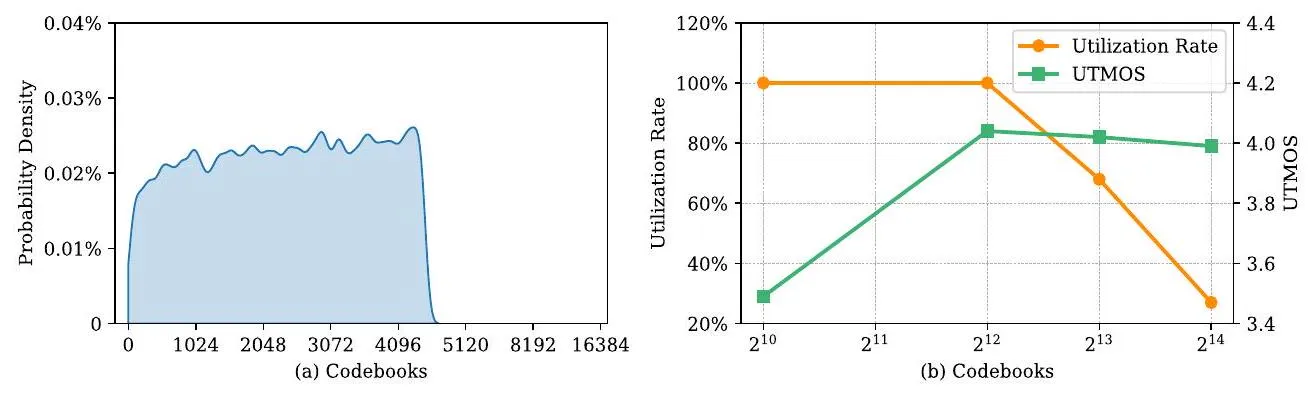
完整流程
① K-means 初始化(训练开始,第一个 batch)
-
聚类中心数 =
codebook_size = 4096 -
迭代轮数 =
kmeans_iters = 200 -
用第一批 encoder 输出的特征向量,跑 4096 个中心、200 轮迭代的 K-means
-
得到的 4096 个聚类中心直接作为 codebook 的初始值
# core_vq.py
embed, cluster_size = kmeans(data, self.codebook_size, self.kmeans_iters)② 前向量化(每个 batch)
-
对每个 encoder 输出的连续向量,算它到 4096 个 code 的欧氏距离
-
选最近的那个 code index → 这就是离散 token ID
-
用 index 查 codebook 表 → 得到量化后的向量
# 距离计算 + 最近邻选择
dist = -(x.pow(2).sum(...) - 2 * x @ embed + ...)
embed_ind = dist.max(dim=-1).indices
# 查表
quantize = F.embedding(embed_ind, self.embed)③ EMA 更新 codebook(每个 batch,训练时)
Codebook 不用梯度更新,而是用 EMA(指数移动平均) 做在线更新,本质是”在线 K-means”:
# 统计每个 code 被分配到多少次
embed_onehot = F.one_hot(embed_ind, self.codebook_size)
ema_inplace(self.cluster_size, embed_onehot.sum(0), self.decay) # decay=0.99
# 统计分配到每个 code 的输入向量之和
embed_sum = x.t() @ embed_onehot
ema_inplace(self.embed_avg, embed_sum.t(), self.decay)
# 更新 code = 加权平均
self.embed.data.copy_(self.embed_avg / cluster_size.unsqueeze(1))④ Dead code 替换(每个 batch,训练时)
-
EMA 统计的
cluster_size如果某个 code 低于阈值(默认 2),说明这个 code 基本没人选 → “死码” -
直接用当前 batch 里随机采样的一个输入向量替换它
expired_codes = self.cluster_size < self.threshold_ema_dead_code # 默认阈值=2
self.replace_(batch_samples, mask=expired_codes)论文 vs 代码的关键差异
| 论文原文 | 实际代码 |
|---|---|
| ”adjust the number of cluster centers to 200” | 200 是 K-means 迭代轮数,不是聚类中心数 |
| 聚类中心数未明确 | 聚类中心数 = codebook 大小 = 4096 |
一句话总结
Codebook 有 4096 个槽位;第一批数据用 4096 中心 × 200 轮 K-means 初始化;之后每个 batch 用 EMA 在线更新 code 向量;长期不用的 code 用当前 batch 的输入向量强制替换。
实际数据流
| 阶段 | 数据形态 | 维度 |
|---|---|---|
| 原始音频 | 浮点数序列 | 24,000 个标量/秒 |
| Encoder 输出 | 连续向量 | 75 个 × 512 维/秒 |
| 量化后(传输的) | token ID | 75 个整数/秒(12 bit each) |
| Decoder 输入 | codebook 查表还原的向量 | 75 个 × 512 维/秒 |
| 重建音频 | 浮点数序列 | 24,000 个标量/秒 |
注意:bitrate 算的是 token ID(12 bit × 75 = 0.9 kbps),不是 embedding 维度。codebook 是共享的查找表,发送方和接收方都有一份,只需传 ID 即可。
实验设置(4.1)
实验在干什么
这是一个 codec 重建质量的横向对比实验,不是下游任务实验。核心问题只有一个:同样的测试集上,WavTokenizer 用极少的 token 能不能比其他 codec 重建得更好?
骨架:
-
训一个 WavTokenizer;其他 baseline(EnCodec / DAC / HiFi-Codec / SpeechTokenizer / Vocos)用官方权重、不重训。
-
在测试集上跑
原始波形 → encode → 量化 → decode → 重建波形。 -
用客观指标(UTMOS / PESQ / STOI / V-UV F1)和主观指标(MUSHRA)比较重建和原始的差距。
-
再单独评两件事:语义信息(ARCH benchmark 分类准确率)和下游 TTS(把 codec 插进同一个 ParlerTTS 600M 骨架,只换 tokenizer。
三个域的划分:语音 / 通用音频 / 音乐
论文把音频粗暴切成三类,训练和测试都按这三类铺开:
| 域 | 里面是什么 | 信号特性 |
|---|---|---|
| Speech(语音) | 人说话 | 稀疏,频率集中在 80–8 kHz,有强时序结构(音素/词) |
| Audio(通用音频) | 除”干净人声”和”纯音乐”外的一切声音:狗叫、开门、引擎、鼓掌、雨声、街道环境、带背景噪的混合声场……英文常叫 general audio / environmental audio / sound events | 谱特征极其多样,无稳定结构,短时瞬态事件多 —— 对 codec 最难压 |
| Music(音乐) | 带旋律、节奏、乐器的音乐 | 有周期性、谐波结构、长程节拍 |
训练数据
总量约 8K 小时,按三个域混合:
| 域 | 数据集 | 时长 |
|---|---|---|
| 语音 | LibriTTS + VCTK + CommonVoice(3000h 采样子集) | ~5K h |
| 通用音频 | AudioSet(2000h 采样子集) | ~2K h |
| 音乐 | Jamendo + MusicDB | ~1K h |
全部统一到 24 kHz 单声道。消融实验用 LibriTTS-only(585h) 的小规模配置。
评测指标
客观指标分两派:传统信号处理派(PESQ / STOI,靠手工设计的听觉模型)和神经网络派(UTMOS,直接预测人会打几分)。
UTMOS —— 核心指标,预测的 MOS
-
输入: 单条重建音频(16 kHz,单声道),不需要参考原始音频 → non-intrusive / reference-free。
-
怎么算: SSL 模型(wav2vec 2.0)提取逐帧表征 → BLSTM + 线性头 → 输出 1–5 的标量。回归头在 BVCC / VoiceMOS Challenge 的人工 MOS 数据(~7000 条音频、每条多人打分平均)上训出来。
-
值域: 1–5,越高越好。真人自然语音通常 4.0+。
-
为什么现在成标配: PESQ 这种传统指标在神经生成音频上常失灵(模型能生成听感自然但波形对不齐参考的语音,PESQ 会误判);UTMOS 和人耳相关性显著更高(Pearson 约 0.89)。
-
局限: 训练数据集中在英语语音,对音乐/环境声/其他语言外推性弱 → 论文里音乐和通用音频用 MUSHRA 主观测,不用 UTMOS。而且 16 kHz 上限,24 kHz 音频要先下采样。
PESQ —— 传统语音质量标准(ITU-T P.862)
-
输入: 成对的(原始, 重建)音频 → intrusive / full-reference。
-
怎么算:
-
时间对齐:先对齐两段音频,避免延迟造成误判。
-
感知建模:两段音频都过一个模拟人耳的感知模型(Bark 频带分解 + 响度变换)。
-
差异聚合:计算两个感知表示的逐帧差异,用非线性聚合压成一个数。
-
最后映射成 MOS 量级。
-
-
值域: −0.5 到 4.5,越高越好。
-
强项: ITU-T 标准,对信号级失真(编码噪声、丢包、回声)敏感 —— 刚好是传统 codec 的主要失效模式。
-
局限: 对神经生成音频偏保守 —— 只要波形和参考对不齐(但听感正常)就扣分。所以表里 DAC 9 kbps 的 PESQ 3.9 vs WavTokenizer 0.9 kbps 的 2.37,不代表后者”难听三分之一”。
STOI —— 短时可懂度
-
输入: 成对音频,full-reference。
-
怎么算:
-
过 1/3 倍频程的滤波器组(模拟人耳频带分辨率)。
-
每个频带上取 ~384 ms 的短时窗口,算窗口内能量包络。
-
原始 vs 重建的包络做相关系数,在所有窗口和频带上平均。
-
-
值域: 0–1,越高越好。
-
在量什么: 短时频带能量包络的相关性 → “听得懂”的前提是包络别崩。只看能不能听懂,不看音质。
-
局限: 对音色、韵律、说话人相似性完全不敏感。重建可能像金属机器人,但只要包络对得上,STOI 照样很高。
V/UV F1 —— 浊音/清音分类 F1
-
输入: 成对音频。
-
怎么算:
-
用基频检测算法(YAAPT / pYIN)逐帧判断原始音频是浊音(voiced,有基频,如元音)还是清音(unvoiced,无基频,如 /s/ /f/)。
-
重建音频做同样判断。
-
把原始的 V/UV 标签当真值、重建的当预测,算二分类 F1 score。
-
-
值域: 0–1。
-
在量什么: 基频相关的保真度。codec 如果把清辅音 /s/ 重建成带基频的东西(常见失败模式),或把浊音重建成无声段,F1 就掉。
-
对 speech codec 尤其重要 —— V/UV 混淆会直接影响听感上的”是不是人在说话”。
MUSHRA —— 多参考多刺激隐藏锚点测试(ITU-R BS.1534)
做法:
-
给评分人听一条参考音频(明确标为 “reference”)。
-
然后听 N 条刺激音频,其中混着:
-
隐藏参考(就是原始音频,伪装成候选)
-
低质量锚点(通常是原始被 7 kHz / 3.5 kHz 低通滤波的退化版)
-
其他系统的重建音频
-
-
每条打 0–100 分,以参考为 100 分的锚。
-
统计每个系统的平均分 + 95% 置信区间(论文里
96.1 ± 2.3的 ± 就是这个)。
为什么比简单 MOS 好:
-
隐藏参考可以过滤不靠谱评分人(给隐藏参考打了 50 分的问卷直接丢)。
-
低质量锚点把评分尺度拉开,避免所有候选挤在 80–100。
-
评分人可以反复切换对比,对细微差异敏感度高得多。
成本:需要 20–40 人众包,单次实验几千刀 → 论文只在少量对比点上跑 MUSHRA。
CMOS (Comparative MOS)
做法:每次给评分人两条音频 A 和 B,问:“相比 A,B 更好还是更差?“打 −3(B 明显更差)到 +3(B 明显更好),0 表示一样。
-
CMOS-Q:比音质(Quality)
-
CMOS-P:比 prosody / 相似度(TTS 中是说话人相似程度)
和 MUSHRA 的区别:MUSHRA 是绝对打分(0–100),CMOS 是相对打分(−3 到 +3)。相对打分对小差异更敏感,所以 TTS 评测喜欢用。Table 4 里把 WavTokenizer 设为 0、DAC 9 kbps = −0.35,意思是”相比 WavTokenizer 合成的 TTS,DAC 合成的平均被评为更差 0.35 档”。
一张全景表
| 指标 | 需参考? | 量什么 | 值域 | 强项 | 短板 |
|---|---|---|---|---|---|
| UTMOS | ❌ | 整体音质(预测 MOS) | 1–5 | 神经生成音频上最准 | 16 kHz、偏英语、偏语音 |
| PESQ | ✅ | 信号级失真 + 听觉建模 | −0.5 到 4.5 | ITU 标准、工业兼容 | 对神经生成偏保守 |
| STOI | ✅ | 可懂度(包络相关性) | 0–1 | 和语音识别率强相关 | 不看音质和音色 |
| V/UV F1 | ✅ | 浊/清音判断一致性 | 0–1 | 反映基频保真 | 只看二分类,粗粒度 |
| MUSHRA | ✅ | 主观音质 | 0–100 | 权威,有锚点 + 隐藏参考 | 贵 |
| CMOS | ✅ | 主观 A/B 对比 | −3 到 +3 | 对小差异敏感 | 只能两两比 |
隐藏逻辑 🟡
Table 1 的粗体规则是 “单量化器(Nq=1)组内 SOTA”,不是全表 SOTA —— 这点 caption 写得很清楚。所以要分两个比较框架看 WavTokenizer:
-
公平赛道(单量化器组内):WavTokenizer 0.9 kbps 对 DAC 1 kbps,在 UTMOS / PESQ / STOI / V-UV F1 四项客观指标上全部加粗 SOTA,MUSHRA 也从 58.4 拉到 96.1,差距压倒性。
-
跨 bitrate 叙事(0.9 kbps vs DAC 9 kbps):这是论文对外宣传的口号。在人耳相关指标上成立 —— UTMOS 4.05 vs 3.91、MUSHRA 三个域都追平或超过;但在波形对齐指标上不成立 —— PESQ 2.37 vs 3.91、STOI 0.91 vs 0.97 差距依然明显。
一句话:WavTokenizer 学到的是”听起来对”,而不是”波形对得上参考”。对下游 LALM / TTS 前者更重要,对通信链路质检后者是硬约束。
下游 TTS 评测框架
不是拿 WavTokenizer 直接 TTS,而是把它插进一个固定的 LM:基于 ParlerTTS 600M 改的 MusicGen 风格自回归模型,只换 tokenizer,其他全相同。这样 TTS 质量差距就只归因于 tokenizer 本身。