Important
原文:Step-Audio 2- An End-to-End Multi-Modal Large Language Model for Audio Understanding and Speech Conversation,StepFun Audio Team。2025 年技术报告。本文只按原论文的顶层章节做框架性梳理,不涵盖细节实验和公式推导。
TL;DR
Step-Audio 2 是 StepFun 推出的端到端多模态音频大语言模型。
它真正的主打卖点只有一个——副语言理解能力:也就是让模型听得懂情感、音色、节奏、风格、声音事件和场景,然后在语音对话里把这种理解顺畅地返哺成有表现力的回复。
围绕这个核心,论文做了三件事:
把离散音频 token 的生成直接纳入 LM 建模、
用以推理为核心的强化学习打磨理解能力、
再通过 RAG 和外部工具(含首次提出的 audio search)补一层真实世界知识
至于 ASR 与语音翻译,数字虽然也是 SOTA,但在作者的叙事里更像是”基础能力不能掉”的门槛项,而不是独立卖点。外部工具调用则属于锦上添花,为”智能”这条主线再叠一层证据。
1. 引言:这篇论文想解决什么
站在作者视角,当前 LALM 生态依然存在三个未解决的问题。第一,以 GLM-4-Voice、Spirit LM 为代表的早期工作只关心语义对齐,志在捕捉意图的副语言信息(情感、韵律、风格)被忽略。第二,Qwen-Audio 系列、Audio Flamingo 系列虽然能理解副语言信息,却只能输出文本,无法把这种理解返哺到富有表现力的语音回复里。第三,现有模型普遍缺乏对真实世界知识的访问通道,导致幻觉多、音色与风格选择受限。Step-Audio 2 的设计直接围绕这三条痛点展开。
2. 相关工作:四块文献地图
论文将先前研究划为四个板块,可以直接当作该领域的索引来用。一是语音与音频理解,从 adapter 路线到引入副语言信息的 ParalinGPT、SALMONN、Seed-ASR 等。
二是TTS,覆盖从 VALL-E、SPEAR-TTS 到 CosyVoice、SEED-TTS、Kimi-Audio 这条 codec + flow matching 的演化链。
三是语音到语音翻译,从级联式到直接 S2ST(Translatotron 系列、TransVIP)。四是语音对话,以 GPT-4o 为分水岭,整理了 Moshi、Mini-Omni、LLaMA-Omni、Qwen2.5-Omni 等端到端方案。
3. 方法:架构与训练管线
3.1 整体架构
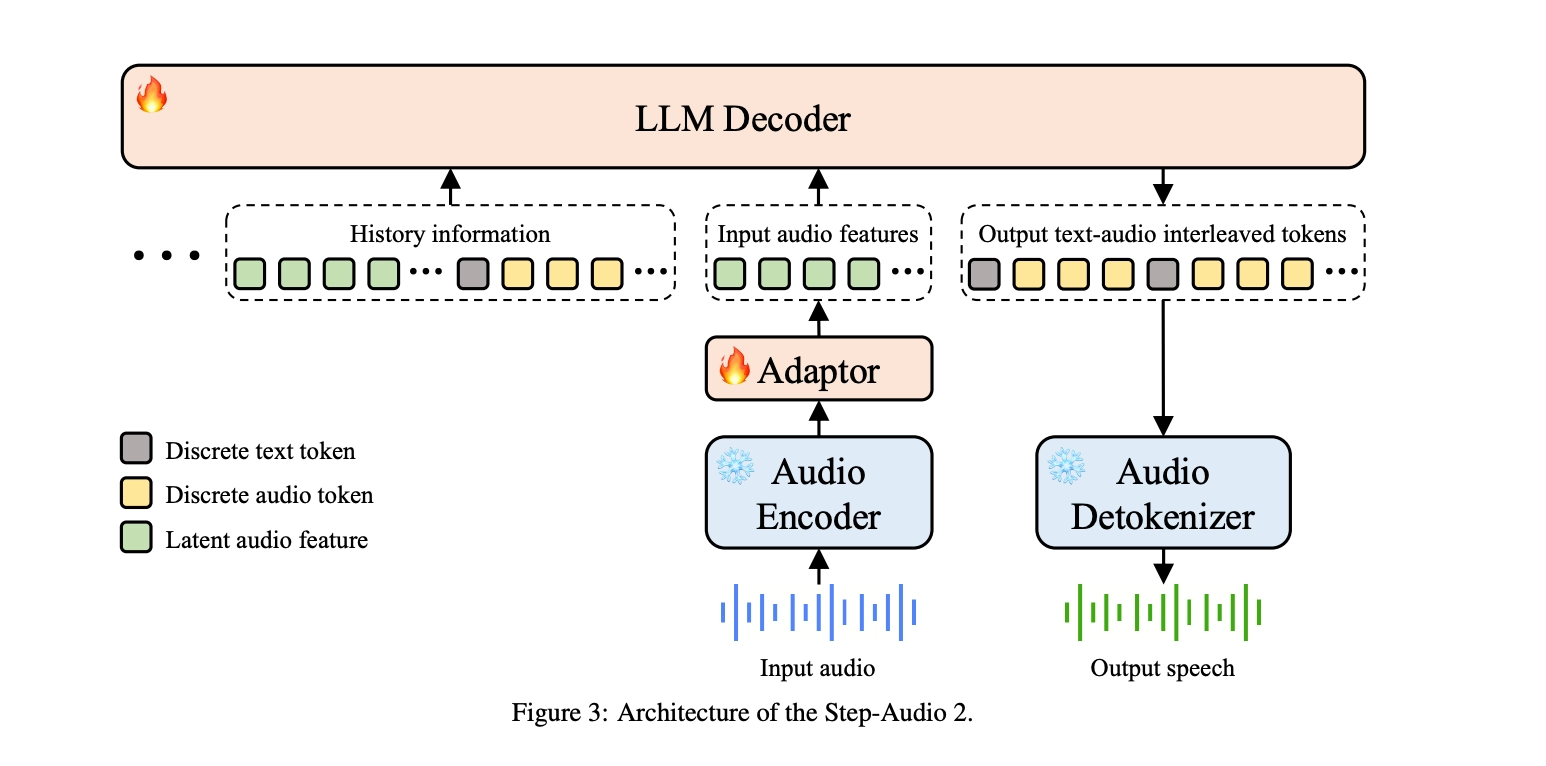
Step-Audio 2 由四个模块组成:冻结的音频编码器(预训练于 ASR、年龄/性别预测、音频事件检测等任务,输出 25 Hz 帧率)、下采样 2 倍的音频适配器(12.5 Hz)、LLM 解码器(输出文本 + 音频 token 交错序列)、音频 detokenizer(复用 CosyVoice 2的 tokenizer,以 Flow Matching + HiFi-GAN 合成波形)。与上一代 Step-Audio 不同的是,音频 token 的生成被直接纳入语言建模,而不再用独立的语音合成模块拼接。
3.2 预训练(四阶段、1.356T token)21 天)
-
阶段一:模态对齐。冻结音频编码器与 LLM,仅训练适配器,用 100B token ASR 数据把音频特征投射到文本嵌入空间。
-
阶段二:tokenizer 扩容。往文本 tokenizer 中加入 6.6K 个音频 token,用 128B + 128B 的文本/音频混合数据训练,保持文本能力的同时让新 token 获得合理嵌入。
-
阶段三:主预训练。800B token,覆盖 ASR、TTS、语音-文本翻译、续写、语音对话等多个任务。
-
阶段四:冷却。200B token 高质量数据,引入多语种与方言 ASR、副语言理解、对话合成等,交由自建对话语音合成管线产出。
3.3 有监督微调(SFT)
在4B token 语料上进行单轮训练,涵盖多语种 ASR、音频事件理解、细粒度语音描述、TTS、S2ST、文本风的口语化对话、工具调用等任务。
论文构造了两组以推理为核心的 SFT 数据,为后续强化学习做冷启动。
3.4 强化学习(三阶段)
第一阶段用二值长度奖励约束思考序列长度(PPO,60 迭代);
第二阶段切换到基于 reward model 的偏好评价(PPO,120 迭代);
第三阶段用 GRPO 迭代 400 次提升音频感知能力。
4. 评测:六个任务面
-
4.1 ASR。在16 个中/英/多语种/方言测试集上,与 Doubao LLM ASR、GPT-4o Transcribe、Kimi-Audio、Qwen-Omni 对比。中文平均 CER 3.08%、英文平均 WER 3.14%,在方言/口音普通话上领先明显。
-
4.2 副语言理解。提出自建基准 StepEval-Audio-Paralinguistic,覆盖性别、年龄、音色、情绪、音高、节奏、语速、风格、人声活动、声音事件、场景 11 个维度。5 5 0 条语音样本,评测由 LLM 自动完成。Step-Audio 2 平均准确率 83.09,大幅领先 GPT-4o Audio、Kimi-Audio、Qwen-Omni。
-
4.3 音频综合理解。在 MMAU 基准上平均 78.0,领先 Audio Flamingo 3、Omni-R1 、Gemini 2.5 Pro 等。
-
4.4 语音翻译。CoVoST 2(语音到文本)与 CVSS(语音到语音)中英双向 BLEU 均领先基线。
-
4.5 工具调用。提出自建基准 StepEval-Audio-Toolcall,测试 audio search / date & time / weather / web search 四类工具的类型选择、触发与参数抽取。Step-Audio 2 在语音输入下与纯文本的 Qwen3-32B 持平,在新提出的 audio search 上明显超过。
-
4.6 语音到语音对话。在 URO-Bench 上中文 basic/pro 均列首,英文败给 GPT-4o Audio 但仍超过其他开源基线。
图示总览
图 1 · 训练管线全谱
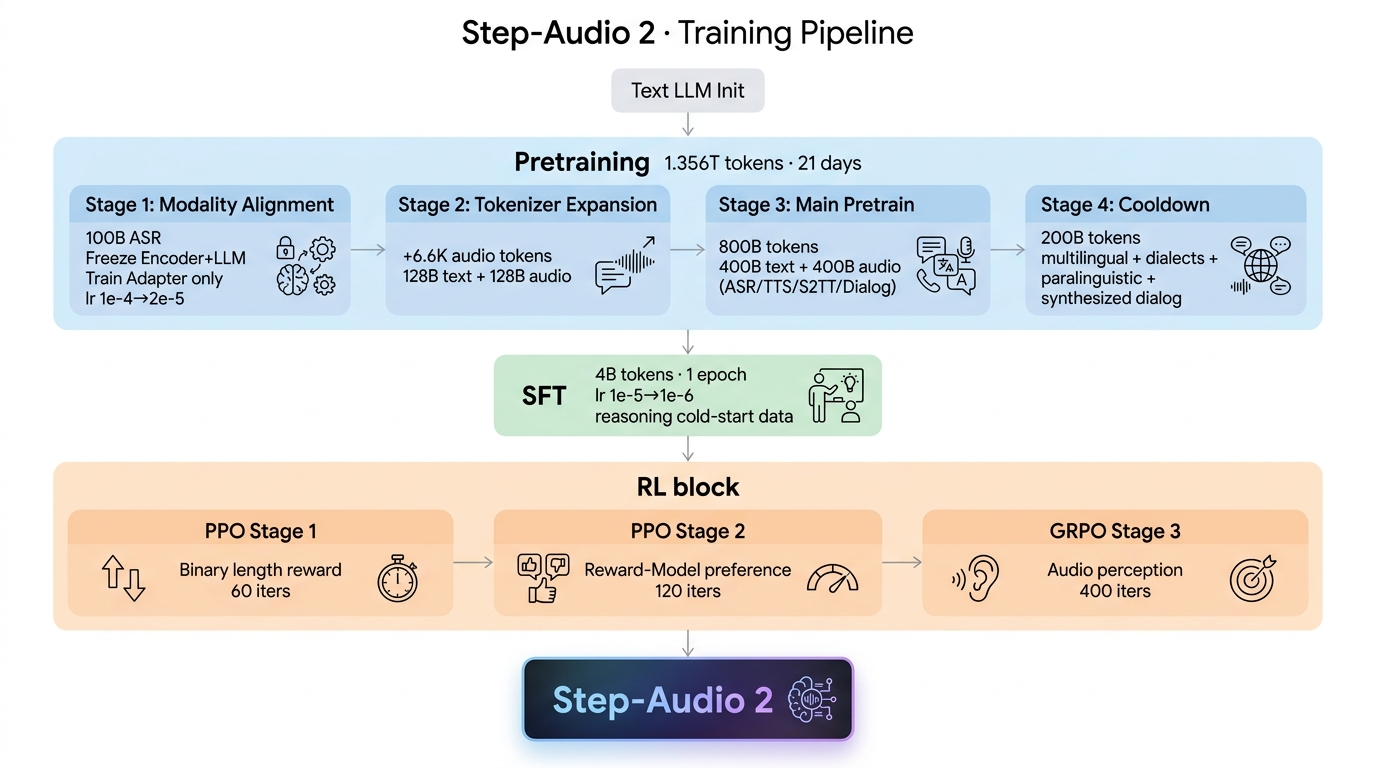
Step-Audio 2 训练管线:文本 LLM 初始化 → 预训练四阶段(1.356T token)→ SFT(4B token)→ RL 三阶段(PPO × 2 + GRPO)→ Step-Audio 2
-
可编辑 Mermaid 版本(便于后续改改数字)
flowchart TD Init["文本 LLM 初始化<br/>继承基础文本模型的权重"] subgraph PT["预训练 · 1.356T token · 21 天"] direction TB P1["阶段 1 · 模态对齐<br/>100B token ASR<br/>冻结 Encoder + LLM<br/>仅训 Adapter<br/>seq=8192 · 12K 步<br/>lr 1e-4 → 2e-5"] P2["阶段 2 · Tokenizer 扩容<br/>+6.6K 音频 token<br/>128B 文本 + 128B 音频<br/>(TTS 80B / 对话 32B / 交错 16B)<br/>seq=16384 · 全量训练<br/>LLM 2e-5 · Adapter 5e-5<br/>Embed 5e-5 · Head 4e-5"] P3["阶段 3 · 主预训练<br/>800B token · lr 2e-5<br/>400B 文本 + 400B 音频<br/>ASR 42B · TTS 120B<br/>S2TT 8B · T2ST 30B<br/>续写 5B · 交错 45B<br/>对话 150B"] P4["阶段 4 · 冷却<br/>200B token · lr 2e-5 → 5e-6<br/>多语种/方言 ASR 24.6B<br/>TTS 12.4B · 副语言 2.4B<br/>S2TT 3.6B · S2ST 6B(合成)<br/>交错对话 15B · 对话 36B(合成)<br/>+ 100B 高质量文本"] P1 --> P2 --> P3 --> P4 end SFT["SFT · 4B token · 1 epoch<br/>lr 1e-5 → 1e-6<br/>多语种 ASR / 音频事件<br/>细粒度副语言描述 / TTS<br/>S2ST / 口语风对话 / 工具调用<br/>➕ 推理型冷启动数据"] subgraph RL["强化学习 · 三阶段"] direction TB R1["阶段 1 · PPO<br/>二值长度奖励<br/>60 迭代 · bs=64<br/>actor 1e-6 · critic 2.5e-6"] R2["阶段 2 · PPO<br/>Reward Model 偏好<br/>120 迭代<br/>bs/lr 同上"] R3["阶段 3 · GRPO<br/>音频感知优化<br/>400 迭代"] R1 --> R2 --> R3 end Init --> PT --> SFT --> RL --> Final(["Step-Audio 2"])
图 2 · 基准地图:分别测什么能力
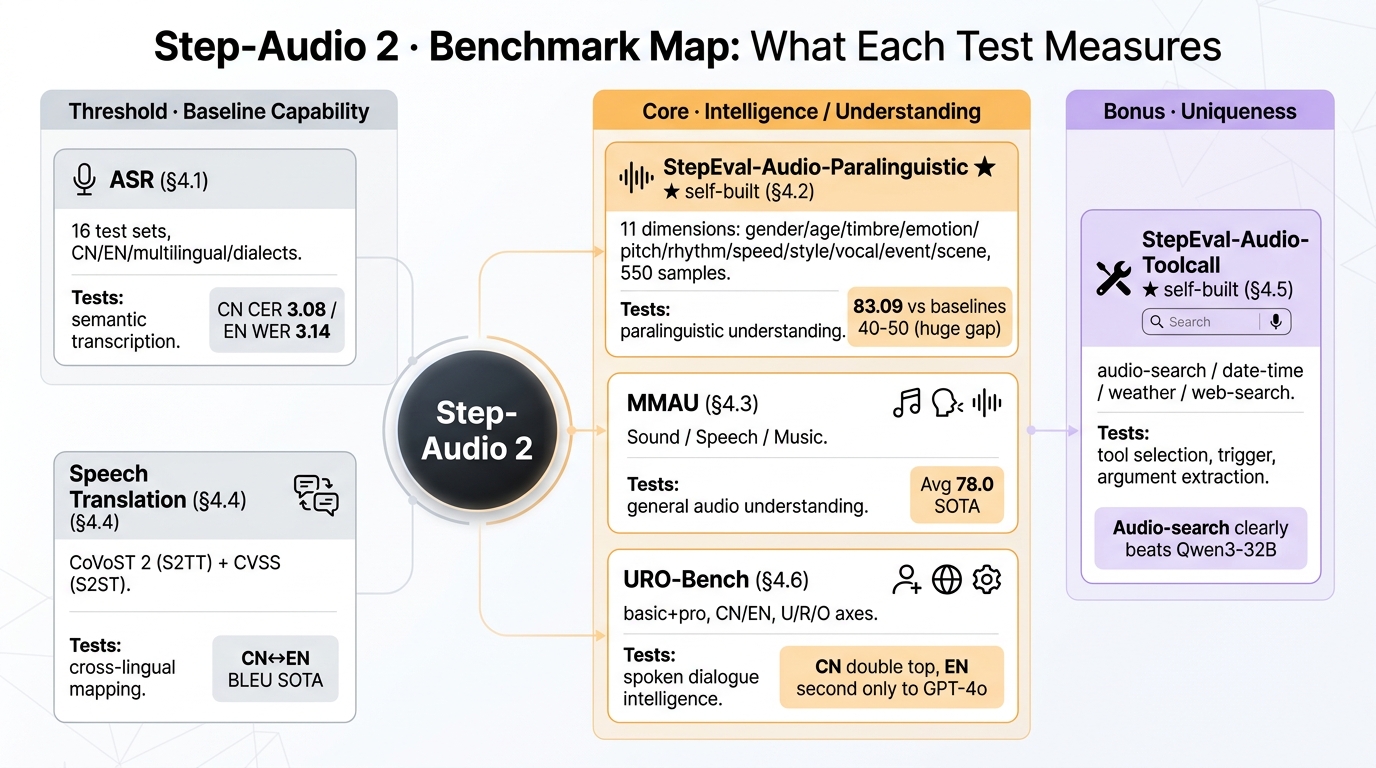
Step-Audio 2 基准地图:门槛项(ASR / 语音翻译)· 主打(StepEval-Audio-Paralinguistic / MMAU / URO-Bench)· 加分项(StepEval-Audio-Toolcall)
-
可编辑 Mermaid 版本
flowchart LR Model(["Step-Audio 2"]) subgraph Threshold["门槛项 · 基础能力不能掉"] direction TB ASR["§4.1 ASR<br/>16 测试集<br/>中/英/多语种/方言<br/>▸ 测:语义转写准确度<br/>▸ 中 CER 3.08 / 英 WER 3.14<br/>▸ 方言·口音跑赢其他"] Trans["§4.4 语音翻译<br/>CoVoST 2(S2TT)<br/>CVSS(S2ST)<br/>▸ 测:跨语言映射<br/>▸ 中英双向 BLEU SOTA"] end subgraph Core["主打 · 智能/理解"] direction TB Para["§4.2 StepEval-Audio-Paralinguistic ★ 自建<br/>11 维:性别/年龄/音色/情绪<br/>音高/节奏/语速/风格<br/>人声活动/声音事件/场景<br/>550 条 · LLM 自动评测<br/>▸ 测:副语言理解<br/>▸ 83.09 vs 基线 40-50 断崖领先"] MMAU["§4.3 MMAU<br/>Sound / Speech / Music<br/>▸ 测:音频综合理解<br/>▸ 平均 78.0 SOTA"] Dialog["§4.6 URO-Bench<br/>basic + pro · 中英<br/>U(理解)/ R(推理)/ O(口语)<br/>▸ 测:语音对话综合智能<br/>▸ 中文 basic+pro 双首<br/>▸ 英文败 GPT-4o 但超其他开源"] end subgraph Bonus["加分项 · 独特性"] direction TB Tool["§4.5 StepEval-Audio-Toolcall ★ 自建<br/>audio search / date&time<br/>weather / web search<br/>▸ 测:工具选择·触发·参数抽取<br/>▸ 语音输入·持平文本 Qwen3-32B<br/>▸ audio search 明显超 Qwen3-32B"] end Model --> ASR Model --> Trans Model --> Para Model --> MMAU Model --> Dialog Model --> Tool
值得留意的点
-
重心判定:副语言理解是真正的主线,自建的 StepEval-Audio-Paralinguistic 上 83.09 vs 基线 40–50 的断崖差距,是全篇最硬的论据;ASR、翻译更像是达标项,工具调用是加分项。
-
将音频 token 纳入 LM 建模是这篇论文对先前 Step-Audio / Step-Audio-AQAA 最大的结构性调整,值得与 Qwen2.5-Omni 的 thinker–talker 架构对照阅读。
-
围绕 RL 的三阶段套路取代了单一奖励信号,但论文未提供每阶段的消融数据,实际贡献分配有待验证。
-
StepEval-Audio-Paralinguistic 与 StepEval-Audio-Toolcall 两个自建基准的构造方式开源可复现,是这篇论文在学术贡献角度较突出的部分。
-
论文反复强调“工业级”定位,但全文未给出部署延迟、实时性等工程指标,阅读时需另行补充底层。