1. Contribution

2. 架构总览
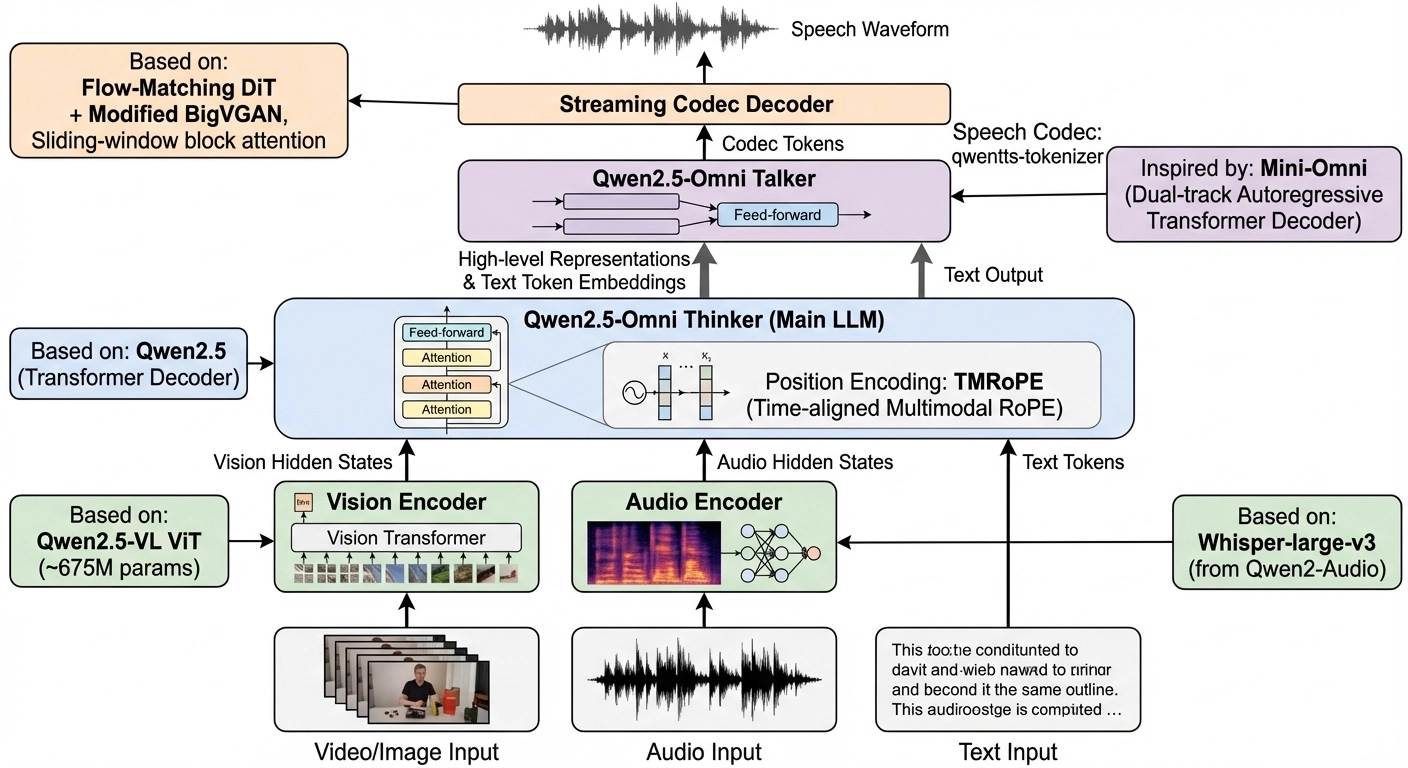
架构图
5 个 Transformer :
| # | 模块 | Transformer 类型 | 来源 |
|---|---|---|---|
| 1 | Vision Encoder | ViT(Encoder) | Qwen2.5-VL |
| 2 | Audio Encoder | Whisper Encoder | Whisper-large-v3 |
| 3 | Thinker | Transformer Decoder(主 LLM) | Qwen2.5 |
| 4 | Talker | 双轨 Transformer Decoder | 受 Mini-Omni 启发 |
| 5 | Codec Decoder (DiT) | Transformer(DiT 架构) | Flow-Matching DiT |
Important
前 2 个是 Encoder(理解侧),中间 2 个是 Decoder(推理 + 语音生成),最后 1 个是 DiT(声学重构)。
输入侧:连续特征表征;输出侧:离散 token → 波形重构。
一段音频的一生:从声波到声波
追踪一段语音在 Qwen2.5-Omni 中的完整生命周期——它在每个模块里长什么样、怎么变形。
🎤 输入侧:用户说了一句话
| 阶段 | 形态 | 发生了什么 |
|---|---|---|
| ① 原始波形 | 1D 连续信号(振幅 × 时间) | 麦克风采集,重采样到 16kHz |
| ② Mel 频谱图 | 2D 矩阵(128 通道 × 时间帧) | STFT + Mel 滤波器组,窗口 25ms,跳跃 10ms → 把时域信号变成时频表示 |
| ③ Audio Hidden | 连续向量序列(每帧 ≈ 40ms) | Whisper Encoder(Transformer Encoder)提取高级语义/声学特征 |
| ④ 进入 Thinker | 与文本/视觉 token 拼接的隐状态序列 | 通过 TMRoPE 对齐物理时间轴,与其他模态一起送入 Thinker 做多模态理解 |
Important
关键变化: 连续波形 → 连续频谱 → 连续隐向量。输入侧始终是连续表征,没有离散化。
🔊 输出侧:模型要说一句话
| 阶段 | 形态 | 发生了什么 |
|---|---|---|
| ⑤ Thinker 输出 | 高层表示 + 离散文本 token | Thinker 自回归生成文本,同时输出每步的隐状态向量(携带语义 + 韵律信息) |
| ⑥ Talker 生成 | 离散 Codec token 序列 | 双轨 Decoder 接收高层表示 + 文本 token,自回归生成 speech codec token(离散编码) |
| ⑦ DiT 解码 | Mel 频谱图 | Flow-Matching DiT 将 codec token → Mel 频谱图(滑动窗口,感受野 4 块,流式生成) |
| ⑧ BigVGAN | 1D 波形 | BigVGAN vocoder 将 Mel 频谱图重建为最终音频波形,流式输出 |
Important
一句话总结: 音频进来时是 波形 → 频谱 → 连续向量(逐步抽象);出去时是 离散 token → 频谱 → 波形(逐步具象)。中间的离散 codec token 是整条链路的信息瓶颈——它决定了语音还原的上限。
3. 关键技术细节
3.0 六大 Attention 机制总览(源码实证)
| 模块 | Attention 类型 | 位置编码 | 注意力模式 | 因果性 |
|---|---|---|---|---|
| Audio Encoder | MHA(标准多头,无 GKV 分组) | 无 | 非因果,cu_seqlens 变长打包 attention | 非因果 |
| Vision Encoder | MHA(无 GKV 分组) | 2D RoPE | 非因果,按 chunk 分段处理 | 非因果 |
| Thinker | GQA(Grouped Query Attention) | 3D mRoPE(section [16,24,24]) | Hybrid:前 28 层 full attn,之后 sliding window(32768) | causal |
| Talker | GQA(复用 Qwen2_5OmniAttention) | 3D RoPE(同 Thinker) | Hybrid(同 Thinker) | causal |
| Codec V2 Decoder | MHA(16 头,无 GQA) | RoPE + 滑动窗口(sliding_window=72) | 因果 + 滑动窗口 | causal |
| DiT | 滑动窗口 block attention | — | 感受野 4 块(lookback 2 + current 1 + lookahead 1) | 非因果(块内) |
3.0.1 Thinker → Talker:隐状态嫁接机制(源码实证)
不是 cross-attention,不是 KV cache 共享,是 additive bias on inputs_embeds。
Thinker 先完整生成文本 → 把 hidden state 传给 Talker → Talker 再串行生成 speech token。
Step 1:Thinker 输出什么
Thinker 自回归生成文本序列后,输出两样东西:
-
hidden_states:最后一层的隐状态向量序列(携带语义 + 韵律信息) -
token_ids:采样出的离散文本 token ID
Step 2:投影到 Talker 维度
# line 3930-3976
talker_inputs_embeds = thinker_to_talker_proj(
thinker_hidden_states[0] # 最后一层 hidden state
+ thinker_token_embeds[0] # 文本 token 的 embedding
)Step 3:Talker 每步解码
Talker 的 token 序列构成:
[codec_mask × input_len] [codec_pad] [codec_bos] → 自回归生成 speech tokens每步 forward 时(line 2373-2375):
inputs_embeds[:, -1, :] = (
projected_thinker_hidden # Thinker 的语义(additive bias)
+ speech_token_embedding # 当前新生成的 codec token embedding
)
# 然后做 causal self-attention(只在 Talker 自己的 speech token 序列内)关键:谁关注谁
| 模块 | 注意力范围 | Thinker 信息如何进来 |
|---|---|---|
| Thinker | 输入文本 + 音频 + 视频 token 之间互相 attend(causal) | — |
| Talker | 只在自己的 speech token 序列内 causal self-attention | Thinker 的 hidden state 作为 additive bias 加到每步的 inputs_embeds 上 |
Important
本质:prefix conditioning / control signal 注入
Talker 不会”看到” Thinker 的 KV cache,也没有 cross-attention 的 Q→K,V 机制。Thinker 的语义信息是通过 embedding 级别的加法 灌注到 Talker 每一步的输入中——类似 ControlNet 对 UNet 的 additive conditioning。
优势: 零额外 attention 参数 / 梯度可直接回传 / Talker 专注声学建模,语义由 Thinker 决定。
3.1 Thinker-Talker:为什么拆成两个 Decoder
为什么不用一个模型同时出文本和语音?
文本生成需要精确的语义推理(逻辑、知识、事实准确性),语音生成需要连续的声学建模(音高、节奏、停顿)。两者的优化目标不同,共享参数会导致 trade-off——语义准确了但音质差,或音质好了但内容出错。拆成 Thinker + Talker 后各自专注,避免互相干扰。
高层表征传递了什么?
语义 + 韵律。如果只传递文本 token,Talker 只知道“说什么”,不知道“怎么说”——音频 Encoder 提取的声学特征就浪费了。而高层表示还有一个对流式场景特别关键的作用:它隐式编码了当前句子还没生成完的部分的语气倾向(比如是疑问还是陈述)——Talker 在文本还没出完的时候就要开始说话,必须提前“预判”语调走向。
离散 token 为什么能消歧(多音字问题)?
Thinker 的高层表示工作在语义空间——“银行”和“行走”的“行”在语义上完全不同,但如果上下文语义接近(比如都跟“移动”相关),高层表示可能很像。所以光靠隐向量,Talker 无法确定到底读 háng 还是 xíng。
而离散文本 token 是确切的字符 ID,它告诉 Talker:“这个位置要说的字是‘行’,且前面的 token 是‘银’”。有了这个明确的字符序列,Talker 就能通过语言模型学到的音素规则确定发音。
类比: 高层表示 ≈ “这句话的语气和节奏”,离散 token ≈ “逐字的拼音参考”。两者结合才能生成发音正确且语感自然的语音。
与 Mini-Omni 的异同。
-
Mini-Omni:单个共享 Transformer,通过 2-pass sequential batch decoding(两次前向传播)实现 text-first、audio-second。推理时每步要跑两次 forward,计算开销翻倍。
-
Qwen2.5-Omni:独立的 Talker 模块,通过 hidden state passing(隐状态直传)接收 Thinker 的输出。架构解耦后可以做到:
① 端到端联合训练(梯度直接回传);
② 流式单次 forward 生成;
③ Thinker/Talker 可独立扩展。
3.2 TMRoPE:时间对齐的多模态位置编码
-
RoPE → M-RoPE → TMRoPE:多模态位置编码
一、RoPE(Rotary Position Embedding)
1.1 为什么需要位置编码
Transformer 的 self-attention 本身是置换不变的(permutation invariant)——打乱 token 顺序,输出不变。因此必须额外注入位置信息,告诉模型”谁在前、谁在后”。
早期方案:
-
绝对位置编码(Sinusoidal / Learned):给每个位置一个向量,加到 token embedding 上。
-
缺点:难以泛化到训练时没见过的序列长度。
-
-
相对位置编码(Shaw et al. / Transformer-XL):直接修改 attention score 来反映相对距离。缺点:实现复杂,不够通用。
RoPE 的目标:用绝对位置的编码方式,自然地在 attention score 中体现相对位置信息。
1.2 核心思路:旋转 Q 和 K
RoPE 不修改 embedding,而是对 attention 中的 Q(query) 和 K(key) 向量施加位置相关的旋转变换。
具体做法:将 维向量拆成 个二维子空间(即相邻两个维度配对),在每个子空间中施加一个 2D 旋转。
1.3 旋转矩阵的数学形式
对于位置 ,第 个子空间()的旋转矩阵为:
其中频率参数 定义为:
-
越小 → 越大 → 旋转越快 → 捕捉短距离位置关系(高频)
-
越大 → 越小 → 旋转越慢 → 捕捉长距离位置关系(低频)
对整个 维向量,RoPE 构造一个分块对角旋转矩阵:
然后对位置 的 query 和 key 分别做旋转:
1.4 为什么旋转能编码相对位置
旋转矩阵有一个关键性质:。
所以两个位置的 attention score:
内积只依赖相对距离 ,而不是 和 各自的绝对值。
直觉理解:
-
每个 token 的 Q/K 被旋转了一个与其位置成正比的角度
-
两个 token 越远,旋转差越大 → 向量方向偏移越大 → 点积(attention score)自然衰减
-
旋转不改变向量模长 → 语义信息被完整保留,只有”方向”被位置调制
1.5 实际实现(高效计算)
实践中不会真的构造旋转矩阵做矩阵乘法,而是用等价的逐元素公式:
对于向量 ,位置 的 RoPE 变换等价于:
对每一对 都做上述变换, 各不相同。只需逐元素乘加,无需矩阵运算。
1.6 RoPE 的局限
RoPE 给每个 token 一个一维位置 ID(第 1 个、第 2 个…)。纯文本是 1D 序列没问题,但图像/视频是多维的——如果把图像 patch 强行拉平成 1D,模型就丢失了二维空间关系。
二、M-RoPE(Multimodal RoPE)
2.1 核心思路
来自 Qwen2-VL。
问题回顾: RoPE 给每个 token 一个 1D 位置 ID,对纯文本没问题。但图像是 2D 的(行 × 列),视频是 3D 的(帧 × 行 × 列)。如果把一张图的 patch 强行拉成一条线编号 0, 1, 2, …,模型就丢失了”哪些 patch 在同一行、哪些在同一列”的空间信息。
M-RoPE 的解法:把 RoPE 的旋转维度拆成三组,每组独立编码一个坐标轴。
假设 head dim = (比如 ),三等分,每组 维(约 42~43 维):
维度段 维度索引范围 编码的坐标 举例 第 1 组 第 0 ~ 41 维 temporal(时间轴) 文本的 token 序号 / 视频的帧号 第 2 组 第 42 ~ 83 维 height(高度轴) 图像或视频帧中 patch 的行号 第 3 组 第 84 ~ 127 维 width(宽度轴) 图像或视频帧中 patch 的列号 具体地说: 原本 RoPE 是用同一个位置 去旋转所有 个子空间;M-RoPE 改成前 1/3 的子空间用 temporal 位置 旋转,中间 1/3 用 height 位置 旋转,后 1/3 用 width 位置 旋转。三组互不干扰,各自独立做标准 RoPE。
2.2 数学形式
设 token 在三个轴上的位置分别为 ,则旋转矩阵变为:
每组内部仍然是标准 RoPE 的分块对角旋转矩阵,只是各自使用独立的位置 ID。
2.3 不同模态的位置 ID 分配
模态 temporal () height () width () 文本 递增 token ID 同 同 图像 固定(同一帧) patch 行号 patch 列号 视频 帧号 patch 行号 patch 列号 文本三组都填同一个递增值 → 退化为普通 1D RoPE。
2.4 为什么有效
attention score 变为:
其中 分别是两个 token 在时间、高度、宽度上的相对距离。
-
同一帧内两个 patch → ,temporal 旋转抵消,attention 只看 → 保留 2D 空间关系 ✅
-
不同帧同一位置 → ,attention 只看 → 保留时间关系 ✅
-
不同帧不同位置 → 三个分量都有差异 → 时空联合建模 ✅
三、TMRoPE(Time-aligned Multimodal RoPE)
3.1 M-RoPE 遗留的问题
M-RoPE 的 temporal ID 用的是帧序号(第 0 帧、第 1 帧…),但在 Qwen2.5-Omni 中需要同时处理音频和视频,两者采样率完全不同:
-
视频可能 2 FPS → 1 秒 2 组视觉 token
-
音频编码器可能 25 Hz → 1 秒 25 组音频 token
如果都用帧序号,模型无法知道”这段音频 token 和这帧视频 token 其实对应同一时刻”。
3.2 改进:锚定到绝对物理时间
TMRoPE 规定:1 个时间 ID = 40ms。
视频帧率不固定时,帧间的 temporal ID 间隔根据实际物理时间动态计算(而非简单 +1)。音频同样按 40ms 粒度编码。
3.3 各模态的位置 ID 分配
模态 temporal () height () width () 文本 递增 token ID 同 同 图像 固定 patch 行号 patch 列号 视频 patch 行号 patch 列号 音频 同 同 3.4 效果
-
同一时刻的视频帧和音频 token 拿到相同或相近的 temporal ID → 模型天然知道它们时间对齐
-
多模态拼接时,每种模态的起始 ID = 前一个模态的最大 ID + 1 → 不同模态之间位置不冲突
3.5 演化路线总结
graph LR A["RoPE<br>1D 旋转位置编码"] -->|"拆成 3 组维度"| B["M-RoPE<br>temporal × height × width"] B -->|"temporal → 绝对物理时间"| C["TMRoPE<br>时间对齐的多模态 RoPE"] A -->|"适用于"| D["纯文本 LLM"] B -->|"适用于"| E["图像/视频 VLM<br>(Qwen2-VL)"] C -->|"适用于"| F["音频+视频 Omni<br>(Qwen2.5-Omni)"]Important
一句话记忆: RoPE 用旋转编码 1D 相对位置;M-RoPE 把旋转维度拆成 3D 来感知时空;TMRoPE 进一步把时间维度锚到物理时钟,让不同采样率的音频和视频自然对齐。
Important
文本 “describe this image”(5 个 token):
-
token 0: (t=0, h=0, w=0)
-
token 1: (t=1, h=1, w=1)
-
token 2: (t=2, h=2, w=2)
-
token 3: (t=3, h=3, w=3)
-
token 4: (t=4, h=4, w=4)
图像(2×3 = 6 个 patch,temporal 固定为上一个模态最大 ID + 1 = 5):
-
patch(0,0): (t=5, h=0, w=0) ← h,w 从 0 开始没问题!
-
patch(0,1): (t=5, h=0, w=1)
-
patch(0,2): (t=5, h=0, w=2)
-
patch(1,0): (t=5, h=1, w=0)
-
patch(1,1): (t=5, h=1, w=1)
-
patch(1,2): (t=5, h=1, w=2)
后续文本 “is a cat”(从图像最大 ID + 1 = 6 开始):
-
token 6: (t=6, h=6, w=6)
-
token 7: (t=7, h=7, w=7)
-
…
-
3.3 qwen-tts-tokenizer:语音编解码器
定位: 整条链路的信息瓶颈——将连续语音压缩成离散 token,后续所有模块都基于这些 token 工作。
论文透露的信息:
-
自研 codec,名为 qwen-tts-tokenizer
-
设计目标:高效表示语音的关键信息(语义 + 声学特征)
-
支持因果解码(causal decoding),即可以流式地从左到右解码,不需要看到未来的 token
-
输出是离散 token 序列,由后续 DiT 转换为 mel 频谱图
和同类 codec 的对比(推测 + 常识):
| Codec | 特点 | 典型代表 |
|---|---|---|
| 多层 RVQ | 多层残差量化,每层补充前一层的量化误差,音质好但 token 数多 | EnCodec, SoundStorm |
| 单层 codec | 只用一层量化,token 数少,适合自回归生成,但音质依赖后续解码器补偿 | VALL-E 2, CosyVoice |
| qwen-tts-tokenizer | 论文未说明具体架构,但强调“高效”且支持因果解码 → 很可能是单层/少层设计 |
Important
论文没写的: codec 的具体架构(VQ-VAE?RVQ 几层?)、codebook 大小、压缩比率、训练数据——全部没说。这又是技术报告藏私货的典型例子。想知道细节得看代码。
源码扒出来的细节(qwen-tts 0.1.1)
论文藏的东西,代码里全有。qwen-tts-tokenizer 有两个版本:
| 参数 | V1(25Hz,老版) | V2(12.5Hz,新版) |
|---|---|---|
| 帧率 | 25 fps(40ms/帧) | 12.5 fps(80ms/帧) |
| 量化架构 | 不同架构(非标准 RVQ) | RVQ(Residual Vector Quantization) |
| RVQ 层数 | — | 16 层 = 1 semantic + 15 acoustic |
| Codebook 大小 | 4096 / 32768 | 2048 |
| 压缩比 | — | 1920×(24kHz → 12.5Hz) |
| codec 输出形状 | (codes_len,) 单码 | (codes_len, 16) 多码 |
| 解码需要 | xvectors(说话人向量)+ ref_mels | 仅 audio_codes |
| vocoder | DiT → mel → BigVGAN | 端到端 decoder |
V2 Decoder 内部结构(**modeling_qwen3_tts_tokenizer_v2.py**):
-
8 层 Transformer Decoder(Self Attn + MLP + LayerScale + RMSNorm)
-
16 头 Attention,无 GQA(GKV=16)
-
RoPE + 滑动窗口(sliding_window=72)
-
支持 Flash Attention / SDPA / Eager 三种后端
Important
关键发现: V2 的
SplitResidualVectorQuantizer把第 1 层单独做语义量化,后 15 层做声学量化——这和 Talker 只自回归生成 1 个 semantic token(由 Thinker hidden state 引导),再由 DiT/decoder 补全声学细节的设计是吻合的。
3.4.1 Thinker 四阶段训练
Thinker 训练流程总览
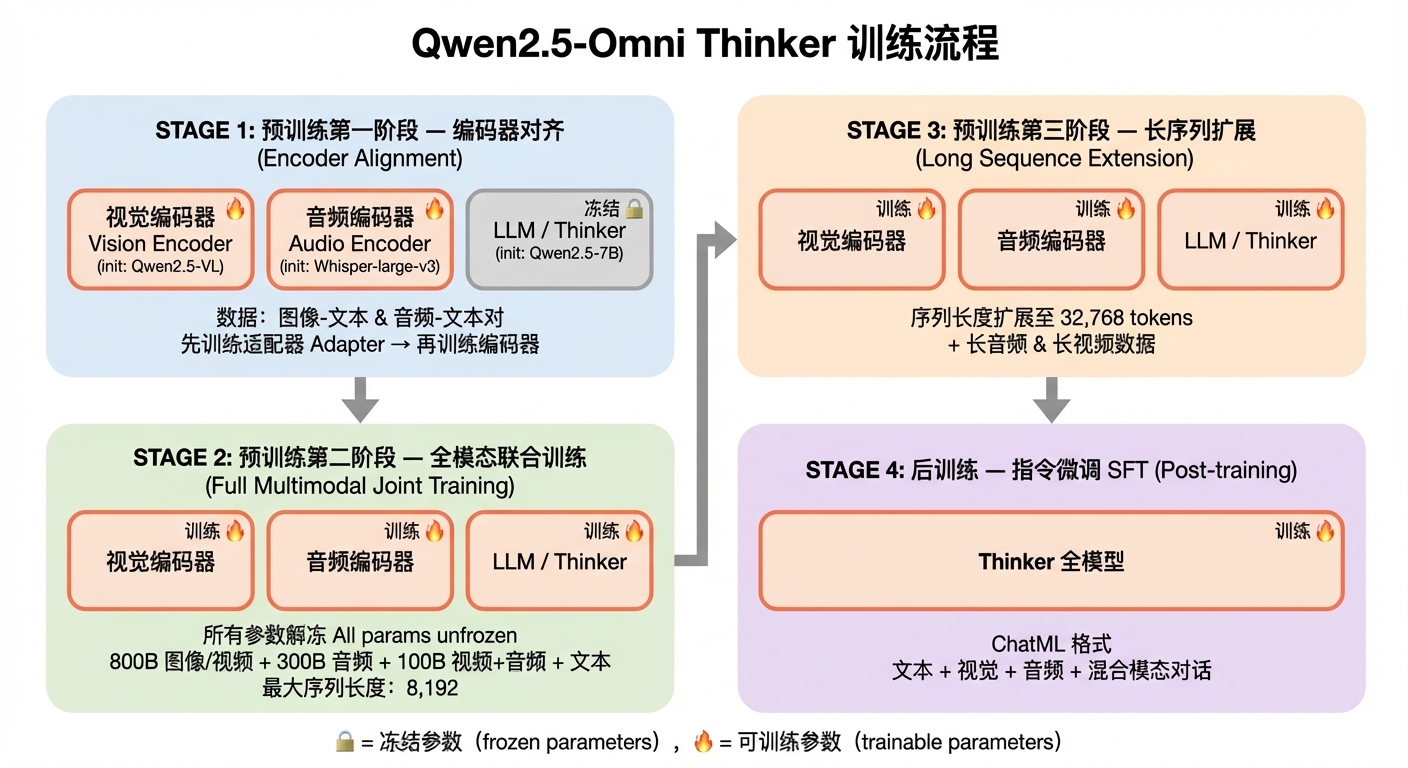
Qwen2.5-Omni Thinker 训练流程
Important
核心思路:递进解冻
Stage 1:冻结 LLM,只训编码器(先 Adapter → 再 Encoder),用 image-text & audio-text 对齐
Stage 2:全参数解冻,800B 图像/视频 + 300B 音频 + 100B 视频+音频 + 文本,seq len 8192
Stage 3:长序列扩展至 32,768 tokens,加入长音频 & 长视频数据
Post-training:ChatML 格式 SFT,文本 + 视觉 + 音频 + 混合模态对话
3.4.2 Talker 三阶段训练
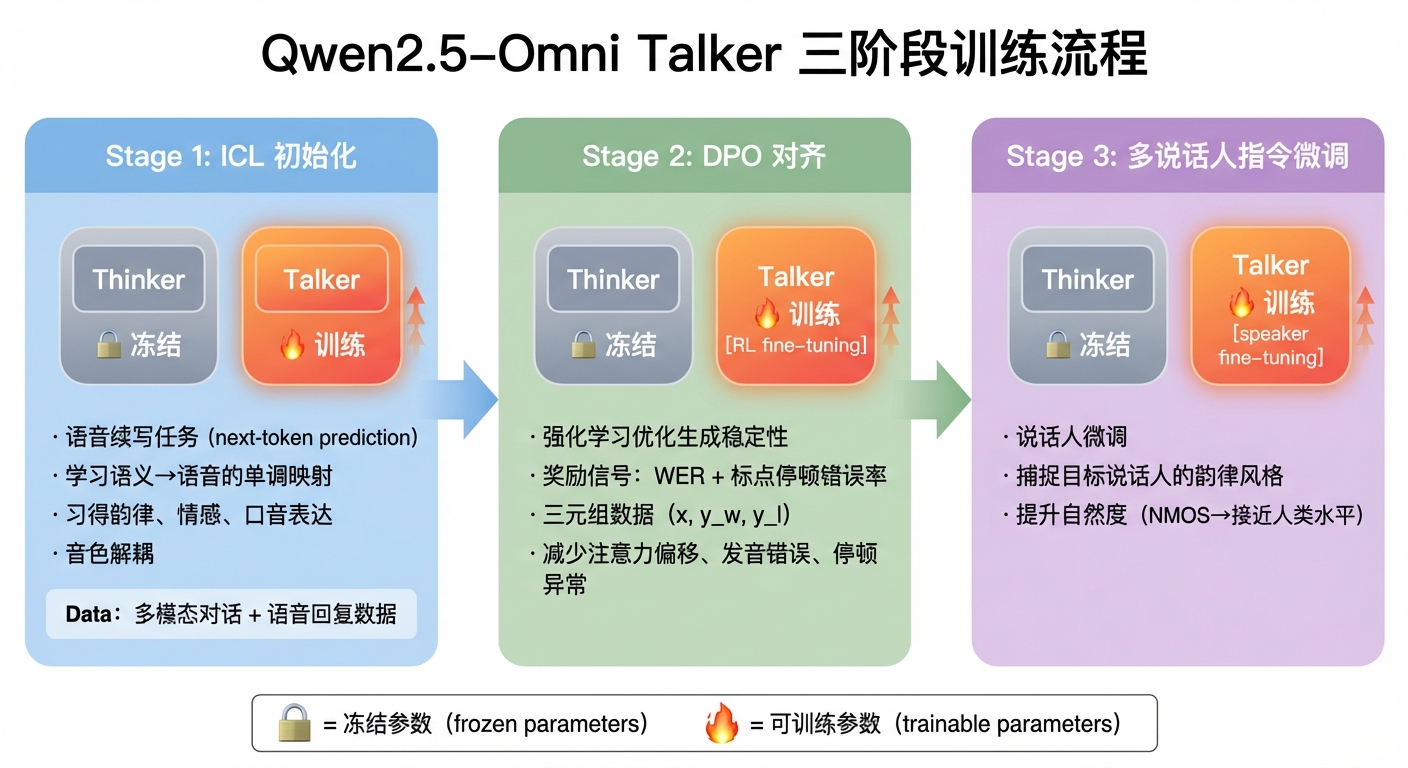
Qwen2.5-Omni Talker 三阶段训练流程
Stage 1: ICL 初始化 → Stage 2: DPO 对齐(WER + 停顿错误率作为奖励信号)→ Stage 3: 多说话人指令微调。
3.5 流式 DiT + BigVGAN:从 codec token 到波形
问题: 标准 DiT 用 full attention,需要看到整段 codec token 才能生成 mel 频谱图——必须等 Talker 全部生成完才能开始,无法流式。
解法:滑动窗口 DiT——每次只处理一个窗口内的块,窗口大小 = 4 块:
| 窗口组成 | 块数 | 作用 |
|---|---|---|
| Lookback | 2 块 | 回看已生成的 mel,保证与前段平滑衔接,不出现拼接断裂 |
| 当前 | 1 块 | 正在生成 mel 的目标块 |
| Lookahead | 1 块 | 偷看后面 1 块 codec token,让当前块的生成能考虑到”接下来的内容”,提升过渡自然度 |
codec token 序列(Talker 逐块输出):
[块1] [块2] [块3] [块4] [块5] [块6] ...
标准 DiT(full attention):
等全部出完 → 一次性生成整段 mel
滑动窗口 DiT(感受野 = 4 块): now lookahead
生成块3的mel → DiT 看 [块1][块2][块3][块4]
↑lookback ↑ ↑
生成块4的mel → DiT 看 [块2][块3][块4][块5]
窗口滑动 →→→代价: lookahead = 1 块,意味着 DiT 要等 Talker 多生成 1 块才能开始处理当前块 → 增加 1 块的延迟。但比起等全部生成完,微乎其微。
DiT 每滑动一步生成一小段 mel → BigVGAN 立刻把这段 mel 转成波形输出。整条链路变成流水线:Talker 出 token → DiT 出 mel → BigVGAN 出声音,三者几乎同时在跑。
3.6 流式推理的工程优化
对语音对话场景,首包延迟(用户说完话到听到模型第一个音的等待时间)是核心体验指标。论文拆解了 4 个延迟来源,并对每个都做了专门优化:
| 延迟来源 | 在等什么 | 论文的优化手段 |
|---|---|---|
| ① 输入处理 | 编码器处理用户的音频/视频 | 编码器分块注意力改造: • Audio Encoder 从全序列 attention 改为每 2 秒一块,不用等整段音频输入完毕; • Vision Encoder 用 Flash Attention + 2×2 patch merge 减少计算量 |
| ② 首个文本 token | Thinker 要“想”出第一个字 | 分块预填充(Chunked Prefill):输入边进来边处理,不用等所有输入处理完再开始生成 |
| ③ 语音转换 | Talker 出 codec → DiT 出 mel → BigVGAN 出波形 | 滑动窗口 DiT(感受野 4 块)+ BigVGAN 逐块生成:不等全部 codec token 生成完,有几块就开始转换 |
| ④ 架构固有 | 模型参数量 / FLOPs 决定的计算时间 | 这个无法算法优化,只能靠硬件加速或模型缩小(如 3B 版本) |
这四个是串行叠加的,总延迟 = ① + ② + ③ + ④。所以优化的核心思路是:把串行变并行,把”等完再开始”变成”边入边出”。
HOW
② Chunked Prefill ,对比普通 Prefill 的时间线:
普通 Prefill:
编码器: [处理块1] [处理块2] [处理块3] [处理块4]
Thinker: 😴 闲着 😴 闲着 😴 闲着 😴 闲着 → [Prefill全部] → [Decode]
↑
编码器全部完成后才开始Chunked Prefill:
编码器: [处理块1] [处理块2] [处理块3] [处理块4]
Thinker: [Prefill块1]
[Prefill块2] // ← 块1的KV Cache已有,只算块2的新部分
[Prefill块3]
[块4] → [Decode]
↑
几乎紧接着就开始核心区别: 编码器干活的时候 Thinker 是闲着还是也在干活——Chunked Prefill 让上游(编码器)和下游(Thinker)的工作在时间上流水线并行,而不是串行排队。
对视频的输入:时间交错法(Time-interleaving)
论文还提出了时间交错法(Time-interleaving),专门针对视频(带音轨)输入:每 2 秒切一个 chunk,块内视觉排前、音频排后交替拼接。
时间交错法 token 排列(以 6 秒视频为例):
┌─── chunk 1: 0~2s ───┐┌─── chunk 2: 2~4s ───┐┌─── chunk 3: 4~6s ─────┐
│[视觉tokens][音频tokens]│[视觉tokens].[音频tokens] [视觉tokens] [音频tokens]│
└──────────────────────┘└───────────────────────┘└───────────────────────┘
不交错(全拼):
[视觉0~6s 全部tokens] [音频0~6s 全部tokens] ← 模型看完 6s 画面才听到第 0s 的声音
交错后:
[视觉0~2s][音频0~2s] [视觉2~4s][音频2~4s] [视觉4~6s][音频4~6s]
↑ 每 2s 视听配对,模型能同步理解这样模型能”看完这 2 秒的画面后立刻听到对应的声音”,实现视听同步理解。
Important
设计哲学: 整个流式设计的核心不是“让每个模块更快”,而是“让模块之间的等待更少”——通过分块 + 流水线,让上游还没出完的时候下游就能开始工作。
4. 实验与评测
论文的评测分两大块:理解侧(X→Text)和生成侧(X→Speech)。
4.1 核心验证:语音输入 ≈ 文本输入?
这是全文最重要的 claim——用语音代替文本做指令输入,推理能力几乎不掉。
论文把纯文本 benchmark 的指令转成语音(约 90% 可用),分别用 Qwen2.5-Omni(语音输入)、Qwen2-Audio(语音输入)、Qwen2-7B(文本输入)跑同一套题:
| Benchmark | Qwen2-7B(文本) | Qwen2-Audio(语音) | Qwen2.5-Omni(语音) |
|---|---|---|---|
| MMLU | 69.3 | 33.2 | 65.6 |
| GSM8K | 82.3 | 18.4 | 85.4 ↑ |
| Math23K | 92.3 | 23.0 | 87.1 |
| CEval | 78.4 | 38.6 | 61.1 |
| IFEval | 53.3 | 15.6 | 41.7 |
Important
关键发现:
GSM8K 语音输入(85.4)甚至超过文本输入(82.3)——说明语音编码器不仅没丢信息,Thinker 还能从语音韵律中获得额外线索
MMLU 差距仅 3.7 分(65.6 vs 69.3),相比 Qwen2-Audio 的 33.2 是质的飞跃
CEval 和 IFEval 差距稍大(~12–17 分),可能是中文语音识别误差和复杂指令跟随的损耗
对比 Qwen2-Audio:全面碾压,说明 Thinker-Talker 架构 + 多阶段训练的效果显著
4.2 多模态理解:和同尺寸专项模型打平
一个 Omni 模型能不能在各个单模态上都不拉胯?
🖼️ 图像理解
和同源的 Qwen2.5-VL-7B 对比(共享 Vision Encoder + Thinker 底座):
| Benchmark | GPT-4o-mini | Qwen2.5-VL-7B | Qwen2.5-Omni |
|---|---|---|---|
| MMMU | 60.0 | 58.6 | 59.2 |
| MathVista | 52.5 | 68.2 | 67.9 |
| MMBench-V1.1 | 76.0 | 82.6 | 81.8 |
| DocVQA | - | 95.7 | 95.2 |
| MMStar | 54.8 | 63.9 | 64.0 |
几乎持平 Qwen2.5-VL,MMMU 甚至微超(59.2 vs 58.6)。加了音频能力没有”拖累”视觉能力。
🎧 音频理解
| 任务 | 亮点 |
|---|---|
| ASR | CommonVoice 中文 5.2 WER(超 Whisper-large-v3 的 12.8、Qwen2-Audio 的 6.9) |
| 语音翻译 S2TT | CoVoST2 zh→en 29.4 BLEU(超 Qwen2-Audio 的 24.4、MinMo 的 26.0) |
| 音频推理 MMAU | 平均 65.60(超 Gemini-Pro-V1.5 的 54.90、Qwen2-Audio 的 49.20) |
| 语音交互 VoiceBench | 平均 74.12(超 MiniCPM-o 的 71.69、Baichuan-Omni-1.5 的 71.14) |
全面超越 Qwen2-Audio,在音频推理(MMAU)上大幅领先 Gemini-Pro-V1.5。
🎬 视频理解
| Benchmark | GPT-4o-mini | Qwen2.5-VL-7B | Qwen2.5-Omni |
|---|---|---|---|
| Video-MME (w/ sub) | - | 71.6 | 72.4 |
| MVBench | - | 69.6 | 70.3 |
| EgoSchema | - | 65.0 | 68.6 |
视频理解反超 Qwen2.5-VL——可能因为 TMRoPE + 时间交错让音频轨道也参与了视频理解(比纯视觉 VL 多了听觉信息)。
🌐 跨模态联合:OmniBench
| 模型 | Speech | Sound Event | Music | Avg |
|---|---|---|---|---|
| Gemini-1.5-Pro | 42.67% | 42.26% | 46.23% | 42.91% |
| MiniCPM-o | - | - | - | 40.5% |
| Baichuan-Omni-1.5 | - | - | - | 42.9% |
| Qwen2.5-Omni | 55.25% | 60.00% | 52.83% | 56.13% |
Important
OmniBench 大幅领先第二名 13+ 个点(56.13% vs 42.91%)。这是论文最亮眼的单一数字——证明 Qwen2.5-Omni 在”需要同时理解多种模态”的场景下优势巨大。
4.3 语音生成质量:和专用 TTS 比
端到端 Omni 模型的语音输出,能打得过专门做 TTS 的系统吗?
Zero-Shot 语音生成(SEED 评测集)
| 模型 | test-zh WER(%) ↓ | test-en WER(%) ↓ | test-hard WER(%) ↓ | test-zh SIM ↑ |
|---|---|---|---|---|
| Seed-TTS (RL) | 1.00 | 1.94 | 6.42 | 0.801 |
| MaskGCT | 2.27 | 2.62 | 10.27 | 0.774 |
| CosyVoice 2 | 1.45 | 2.57 | 6.83 | 0.748 |
| F5-TTS | 1.56 | 1.83 | 8.67 | 0.741 |
| Qwen2.5-Omni (ICL) | 1.70 | 2.72 | 7.97 | 0.752 |
| Qwen2.5-Omni (RL) | 1.42 | 2.33 | 6.54 | 0.754 |
-
WER:中文 1.42% 超过 CosyVoice 2(1.45%)和 MaskGCT(2.27%),仅次于 Seed-TTS
-
DPO(RL)的效果显著:ICL → RL,test-hard WER 从 7.97 降到 6.54(↓18%),验证了 Stage 2 训练的价值
-
说话人相似度(SIM)中等偏上,不是最强但可接受——毕竟是流式生成,和离线 TTS 比 SIM 天然吃亏
单说话人微调后
| 模型 | test-en WER(%) ↓ | NMOS (zh) ↑ | NMOS (en) ↑ |
|---|---|---|---|
| Human | 2.14 | 4.51 | - |
| Qwen2.5-Omni Speaker B | 1.89 | 4.51 | 4.62 |
| Qwen2.5-Omni Speaker D | 1.83 | 4.48 | 4.58 |
Important
Speaker B 的中文自然度 NMOS = 4.51,与人类录音持平。 英文 NMOS 4.62 甚至超过中文——Stage 3 多说话人微调让生成质量逼近真人水平。
4.4 纯文本能力:Omni 的代价
加了这么多模态,纯文本能力掉了多少?
Qwen2.5-Omni 的文本性能介于 Qwen2-7B 和 Qwen2.5-7B 之间:
| Benchmark | Qwen2-7B | Qwen2.5-Omni | Qwen2.5-7B |
|---|---|---|---|
| MMLU-redux | 67.3 | 71.0 | 75.4 |
| MATH | 52.9 | 71.5 | 75.5 |
| GSM8K | 85.7 | 88.7 | 91.6 |
| HumanEval | 79.9 | 78.7 | 84.8 |
比 Qwen2-7B 强,但比 Qwen2.5-7B 弱 3–6 分。这是合理的——多模态联合训练不可避免地分摊了部分文本优化的 capacity。数学和代码受影响最小。
4.5 总结:实验告诉我们什么
Important
三个核心结论:
语音输入 ≈ 文本输入 被数据验证了——这是 Omni 模型实用化的前提
单一模型不牺牲各模态能力——图像 ≈ Qwen2.5-VL,音频 > Qwen2-Audio,视频甚至反超 VL
语音生成接近专用 TTS 水平——DPO + Speaker FT 两步走,NMOS 逼近人类
论文没做但值得关注的:
没有 ablation 对比 TMRoPE vs M-RoPE 的量化差异
没有 Thinker-Talker vs 单模型的消融
没有首包延迟的具体数字(只描述了优化方法,没报 ms 级指标)
没有全双工对话的评测
5. Future Work
论文明确提到的
-
更大规模模型:当前开源的是 7B,未来可能探索更大参数量的 Thinker(类比 Qwen2.5-72B),进一步提升多模态理解能力
-
更多语言支持:当前语音生成主要支持中英,扩展到更多语种的语音合成
-
更丰富的语音控制:_情绪、语速、音色_的更细粒度可控生成
Important
一句话总结: Qwen2.5-Omni 解决了“听懂 + 说出来”的问题,但距离理想的实时多模态对话体(全双工、任意模态输入输出、细粒度可控)还有明确的距离。