论文信息
-
标题: Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
-
作者: Yunfei Chu*, Jin Xu*, Xiaohuan Zhou*, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou†, Jingren Zhou(阿里巴巴)
-
arXiv: 2311.07919v2
-
代码与模型: GitHub
Very SOTA
Motivation
现状问题:
-
现有音频模型大多是任务专用的(task-specific),每个模型只处理一种音频任务(如 ASR、音频事件检测、语音情感识别等),无法泛化
-
尝试多任务联合训练时,会出现任务干扰(interference)问题 — 不同任务的优化目标相互冲突,导致性能下降
-
音频信号种类繁多(语音、音乐、环境声),现有模型难以在统一框架下同时处理所有类型
灵感来源:
-
大语言模型(LLM)在 NLP 领域展现了强大的统一建模能力
-
视觉-语言多模态模型(如 LLaVA)成功将视觉理解统一到 LLM 框架中
-
但音频领域还缺少类似的统一大规模音频-语言模型
Contribution

Method : 多任务训练格式框架
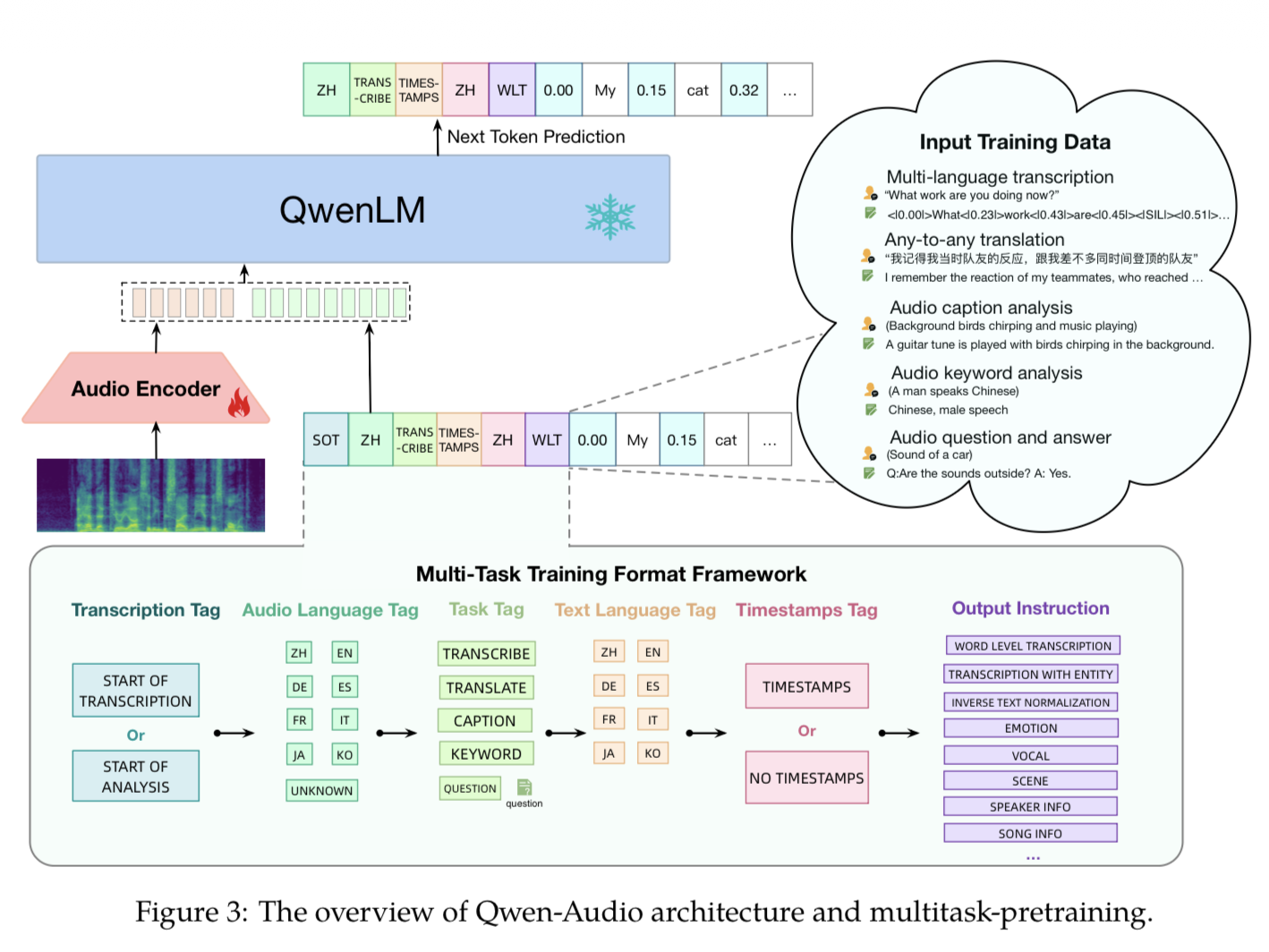
受 Whisper 启发,Qwen-Audio 设计了一套多任务训练格式框架,通过一系列特殊 token(tag)来区分不同音频任务,解决多任务联合训练中的干扰问题。解码序列按以下顺序组织:
| 序号 | 标签名称 | Token 示例 | 作用 |
|---|---|---|---|
| 1 | Transcription Tag(转录标签) | `<\ | startoftranscripts\ |
| 2 | Audio Language Tag(音频语言标签) | 各语言专属 token / `<\ | unknown\ |
| 3 | Task Tag(任务标签) | `<\ | transcribe\ |
| 4 | Text Language Tag(文本语言标签) | 目标语言 token | 指定输出文本的目标语言 |
| 5 | Timestamps Tag(时间戳标签) | `<\ | timestamps\ |
| 6 | Output Instruction(输出指令) | 子任务格式指令 | 进一步指定输出格式,随后开始文本生成 |
设计原则:通过共享标签最大化相似任务间的知识共享;同时通过不同标签组合区分任务和输出格式,避免一对多映射问题。
监督微调(SFT)
经过多任务预训练后,模型已具备广泛的音频理解能力。在此基础上,采用**指令微调(instruction-based fine-tuning)**使模型对齐人类意图,得到交互式聊天模型 Qwen-Audio-Chat。
数据构造:
-
为每个任务人工创建示范(demonstration),包含原始文本标签、问题和答案 — seed data
-
利用 GPT-3.5 基于原始标签进一步生成问答对 — data augmentation
-
通过人工标注 + 模型生成 + 策略拼接,构建音频对话数据集,引入推理、故事生成和多音频理解能力
多音频对话:
-
用
Audio id:标记不同音频(id 对应输入顺序) -
对话格式采用 ChatML 格式,每条交互用
<im_start>和<im_end>标记起止
Results
Benchmarks
关键结论:
-
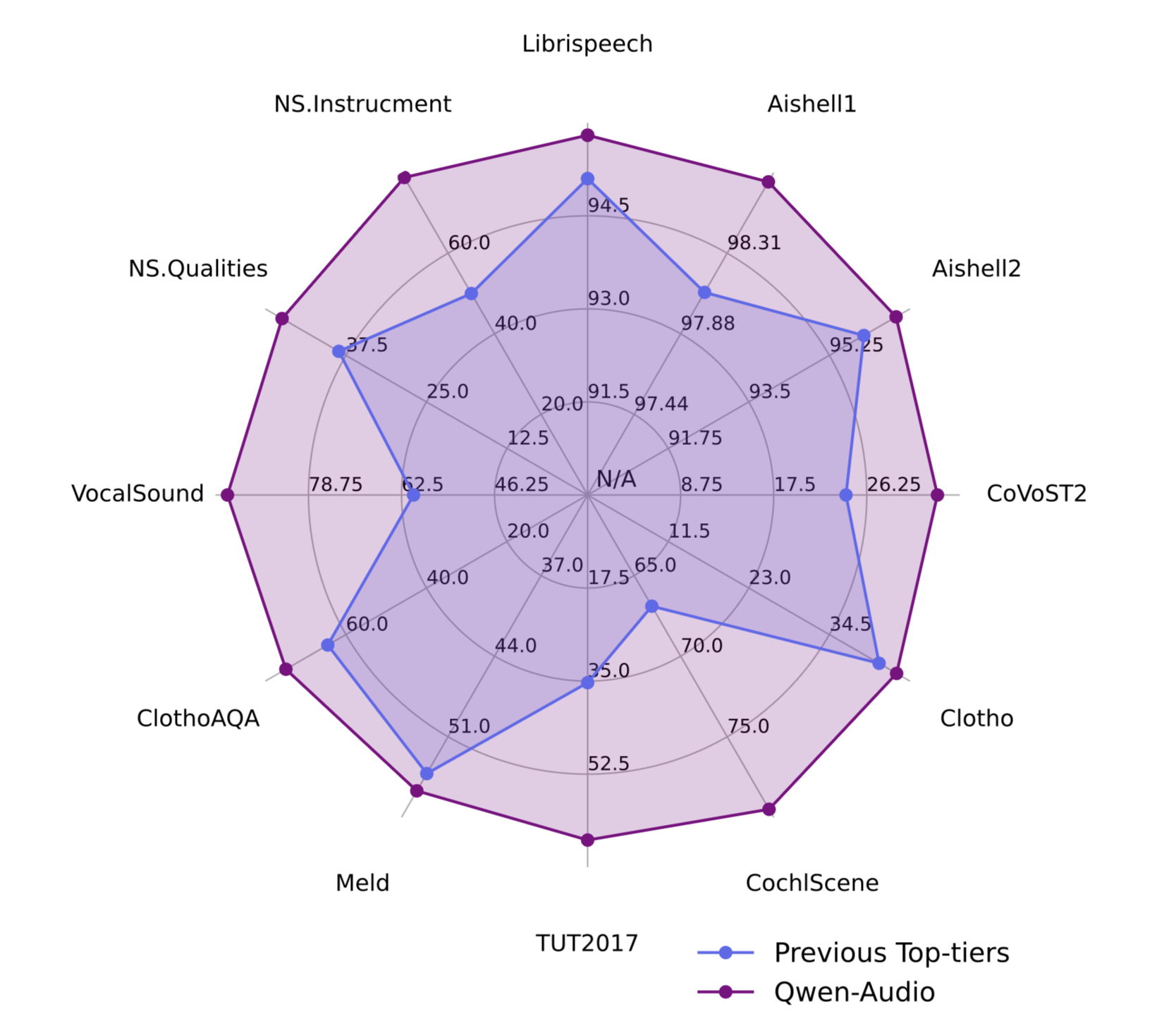
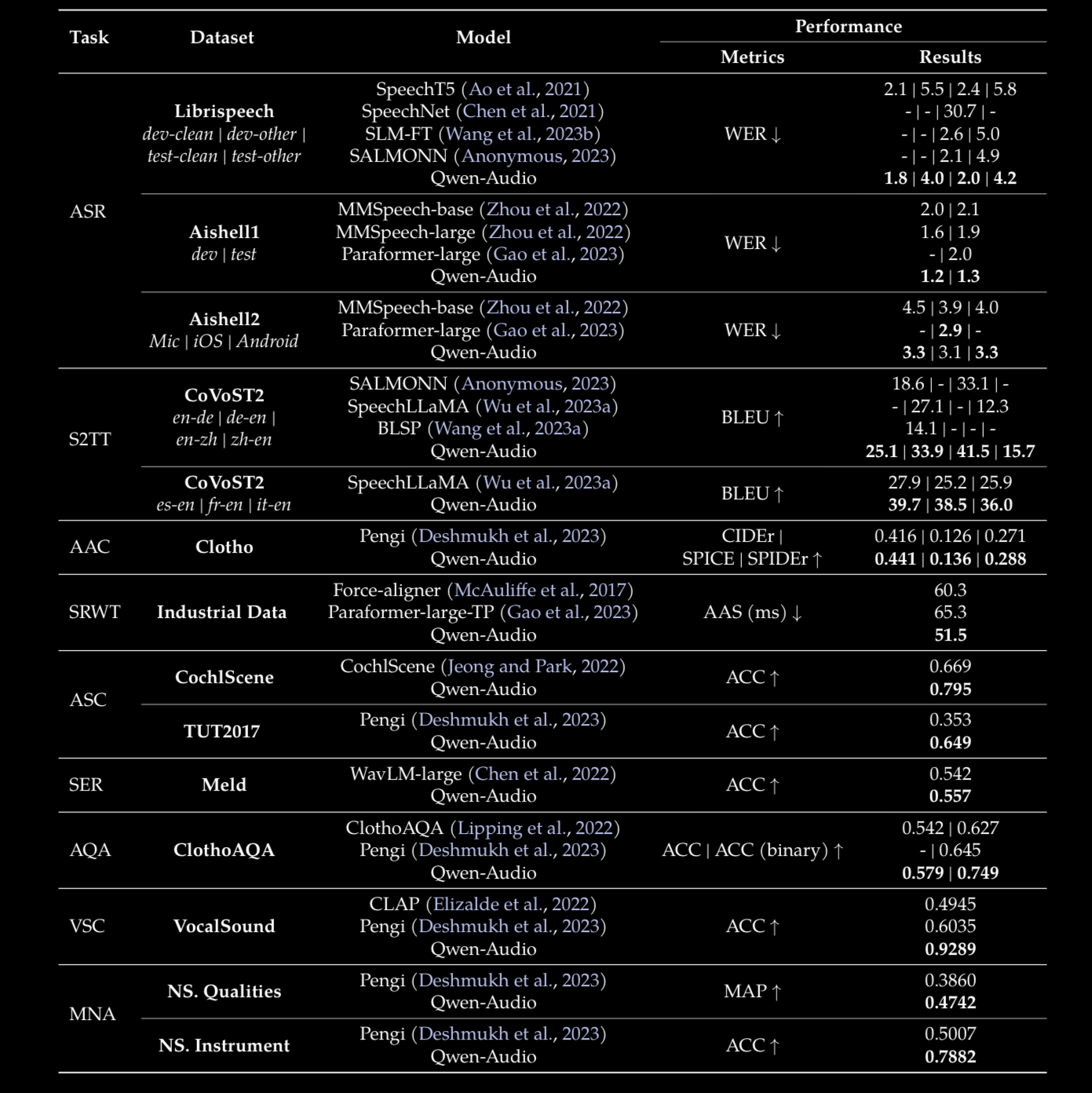
Qwen-Audio 无需任何任务特定微调,在 12 个 benchmark 中全面超越先前 SOTA,覆盖 ASR、语音翻译(S2TT)、音频描述(AAC)、语音情感识别(SER)、声学场景分类(ASC)、音频问答(AQA)等多个任务
-
与 task-specific 的专用模型(如 Paraformer、SpeechT5、WavLM-large 等)相比,统一模型反而取得了更好的性能,说明多任务联合训练带来了正向的知识迁移
-
在 ASR 任务上,Qwen-Audio 在 Librispeech test-clean/test-other 和 AISHELL1 上均达到极低的 WER,接近甚至超越专用 ASR 系统
-
在非语音任务(环境声分类、音乐 QA 等)上同样表现优异,验证了模型对多类型音频的通用理解能力
-
Qwen-Audio-Chat 经过 SFT 后,在交互式音频对话场景中展现了强大的指令跟随和多轮对话能力
消融实验:SRWT 的贡献
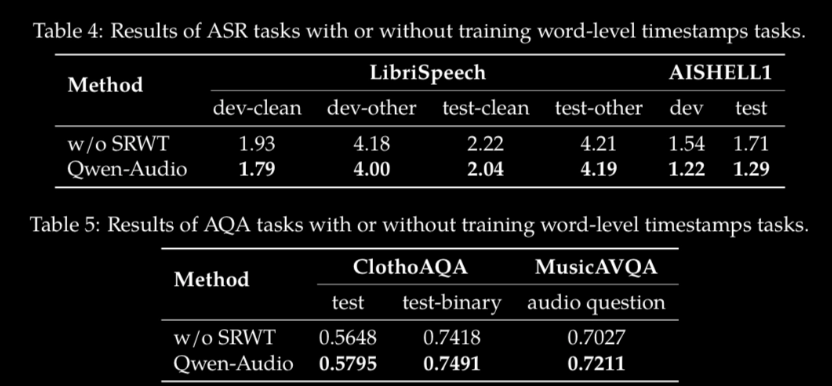
关键结论:
- 去除 SRWT 任务后(w/o SRWT),ASR 的 WER 在所有测试集上均性能下降,说明 SRWT 对纯语音识别有正向增益
Important
SRWT 与 ASR 共享相同的音频数据集,因此去除 SRWT 不影响数据覆盖范围,性能差异纯粹来自于词级时间戳训练信号的贡献
- 加入 SRWT 还提升了音频问答(AQA)和音乐 QA 等非 ASR 任务的表现,说明细粒度的时间对齐能力增强了模型对音频信号的通用定位能力(grounding ability)