Perception-to-understanding curriculum 是 LTU 训练时用的一种由易到难的课程式训练策略,核心思路是:先让模型学会”听清楚”,再教它”理解”。
具体分四个阶段:
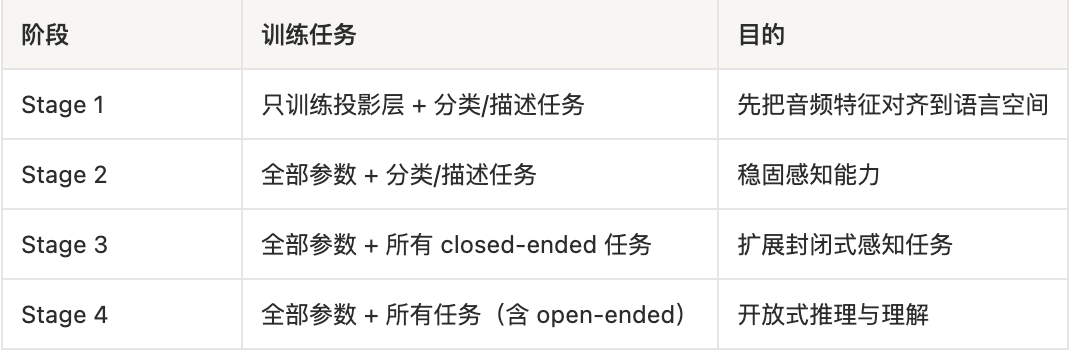
Perception-to-understanding curriculum
论文定位
历史价值 > 技术价值。 LTU 是最早把 audio encoder 接进 LLM、做开放式音频理解的工作之一(2023年初),技术选择放到今天全是标配,但它趟了路——证明这条路走得通。Qwen-Audio、SALMONN、Gemini Audio 都是这条路延伸出去的。
架构要点
-
音频侧: 原始音频 → Mel 频谱(128×1024)→ AST patch 编码 → Pooling(同一时间步频率维度压缩)→ Projection(2× 下采样)→ 32 个音频 token
-
拼接方式:
[A1...A32] + [文本 token]统一送进 LLaMA,用 RoPE 统一位置编码,模型靠训练学会区分音频/文本 token -
LLM 骨干: LLaMA-7B,冻结本体,只训 LoRA + Projection;AST 同样冻结
Train Recipe 决策链
| 节点 | 决策 | 动机 |
|---|---|---|
| 冻结 LLaMA | 只训 LoRA | 全量微调太贵;语言能力不需要改 |
| 冻结 AST | Projection 做桥梁 | 避免两侧同时更新导致收敛混乱 |
| 两阶段训练 | Closed-Ended → Open-Ended | 由易到难,先建基础感知再学推理 |
| 2× 下采样 | 压成 32 token | context window 有限,消融选出的甜点 |
| 答案用规则、问题用 GPT | 准确性 vs 多样性分工 | GPT 答案有幻觉风险,会污染监督信号 |
本质是工程师思维的 pragmatic 方案:每个可能出问题的地方找最省力的解法,不是从理论推导出来的。
一个反直觉的设计亮点
约 6.5% 的 GPT 生成问题无法从音频中回答,对应答案是 “it cannot be determined from the audio that…”。作者没有丢掉这些样本,理由是:教模型说”我不知道”和教模型说正确答案同等重要,可以减少幻觉。
类比:SQuAD 2.0 加入无法回答的问题,让阅读理解模型学会拒答。
总体评价
除课程学习策略和”拒答样本”设计外,LTU 没有太多值得单独记忆的技术点。读它的目的是建立音频 LLM 领域的地图感,理解这个范式的起点在哪里。