1. 一图概览
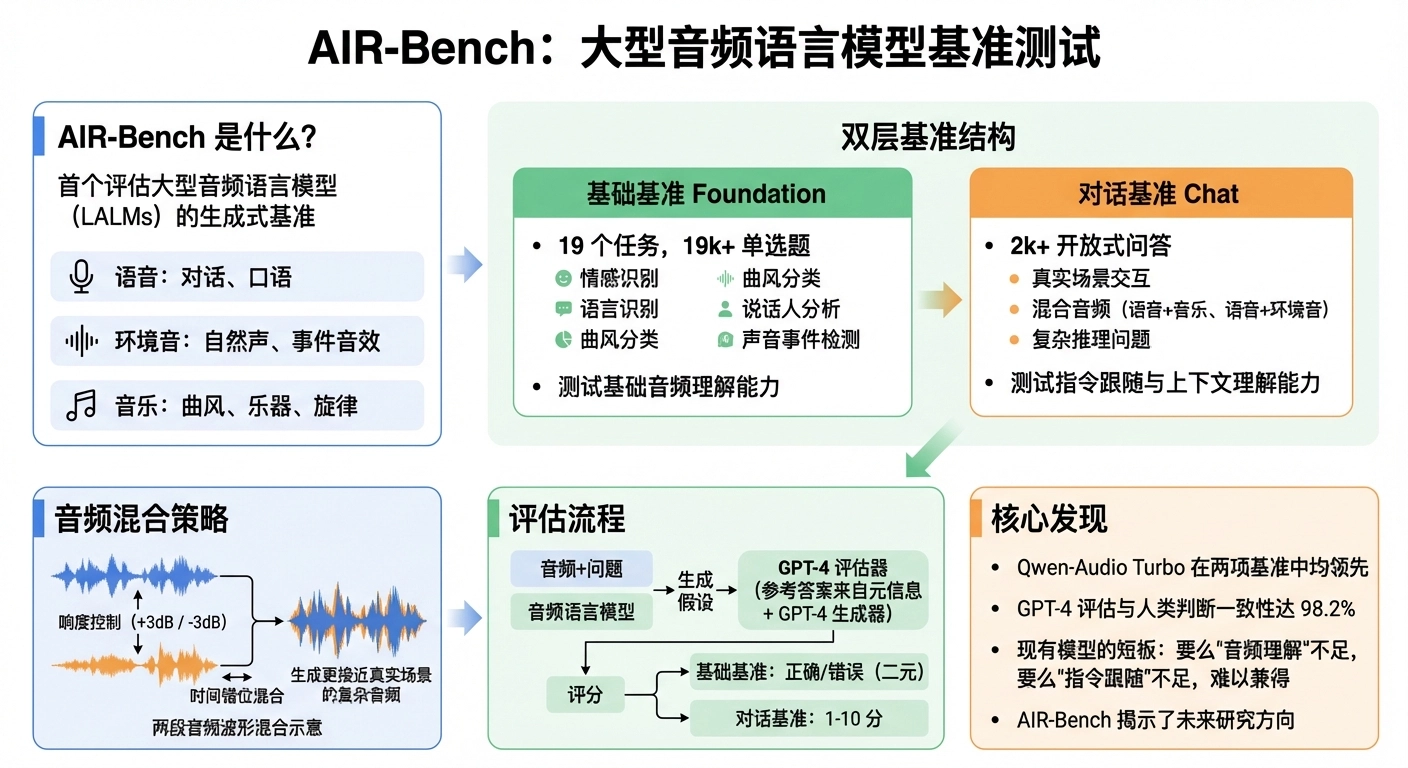
2. 动机:为什么需要 AIR-Bench
现有评估的三重缺失
Important
任务粒度太细,只测单项能力
已有基准都是”一对一”:LibriSpeech 测 ASR、Common Voice 测多语种 ASR、IEMOCAP 测情感识别、Clotho 测音频描述、MusicCaps 测音乐描述…… 每个只考一道题,无法反映 LALM 的综合能力。
Important
综合基准只评 SSL 模型,不评 LALMs
SUPERB 和 HEAR 虽然是综合基准,但设计目标是评估自监督学习的表征质量(冻结 encoder + 线性探针),不适用于评估端到端指令跟随的 LALMs。
Important
唯一的指令跟随基准覆盖面不够
Dynamic-SUPERB 是当时唯一面向 LALMs 指令跟随能力的基准,但只涵盖人类语音,不覆盖环境音和音乐,且不支持开放式生成评估——只能做分类。
结果:行业痛点
各模型(SALMONN、Qwen-Audio、BLSP 等)只能靠展示 demo 或开放 API 来暗示对话能力,无法做公平客观的横向对比,也看不清自身的具体短板在哪。
AIR-Bench 的定位
首个统一评估 LALMs 在语音、环境音、音乐三类音频上的生成式理解与交互能力的基准。
三大特性:
-
全面的音频覆盖——Speech + Sound + Music + Mixed Audio
-
层级化基准结构——Foundation(基础能力诊断)+ Chat(开放式交互)
-
统一、客观、可复现的评估框架——基于 GPT-4 的自动评估,与人类高度一致
3. 基准设计 ⭐ 核心
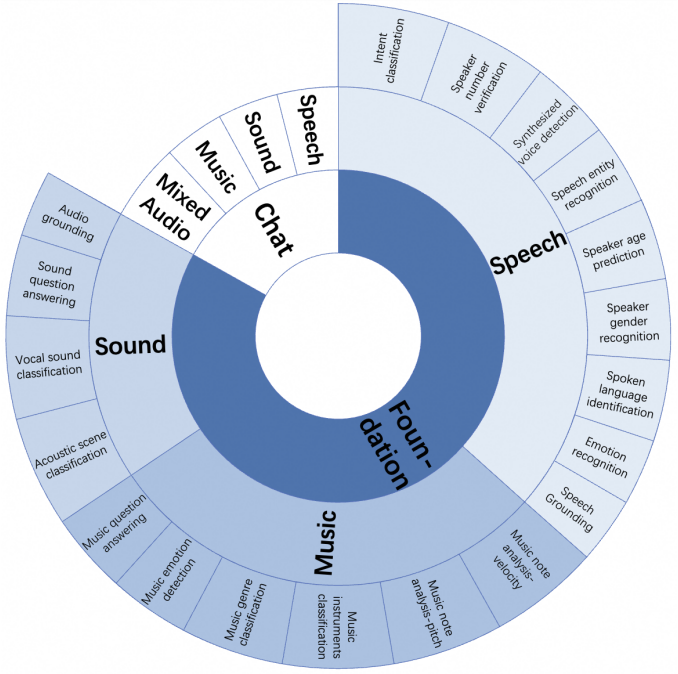
3.1 整体架构:Foundation + Chat
| 基础基准 Foundation | 对话基准 Chat | |
|---|---|---|
| 定位 | 诊断各项基础能力的短板 | 评估真实场景下的复杂音频交互 |
| 规模 | 19 个任务,~19k 单选题 | 2k+ 开放式 QA |
| 音频类型 | 语音 / 环境音 / 音乐 | 语音 / 环境音 / 音乐 / 混合音频 |
| 题目形式 | 四选一单选(二分类任务为二选一) | 开放式生成(感知 / 推理 / 创作) |
| 数据表示 | (A, Q=(q,C), R=正确选项) | (A, Q=开放式问题, R=GPT-4 参考答案) |
设计哲学:Foundation 像”单项体检”,一项一项查;Chat 像”综合考试”,直接看能不能在真实场景里跟人对话。
3.2 Foundation Benchmark 详解
19 个子任务一览
| 类别 | 任务 | 数据来源 | 数量 |
|---|---|---|---|
| 语音(9) | 语音定位(Speech Grounding) | LibriSpeech | 0.9k |
| 语种识别 | CoVoST2 | 1k | |
| 说话人性别识别 | Common Voice, MELD | 1k | |
| 情感识别 | IEMOCAP, MELD | 1k | |
| 年龄预测 | Common Voice | 1k | |
| 语音实体识别 | SLURP | 1k | |
| 意图分类 | SLURP | 1k | |
| 说话人数量验证 | VoxCeleb1 | 1k | |
| 合成语音检测 | FoR | 1k | |
| 环境音(4) | 音频定位(Audio Grounding) | AudioGrounding | 0.9k |
| 人声分类 | VocalSound | 1k | |
| 声学场景分类 | CochlScene, TUT2017 | 1k | |
| 声音问答 | Clotho-AQA, AVQA | 1k | |
| 音乐(6) | 乐器分类 | NSynth, MTG-Jamendo | 1k |
| 曲风分类 | FMA, MTG-Jamendo | 1k | |
| 音符音高分析 | NSynth | 1k | |
| 音符力度分析 | NSynth | 1k | |
| 音乐问答 | MUSIC-AVQA | 0.8k | |
| 音乐情感检测 | MTG-Jamendo | 1k |
💡 ASR 等转录任务不在 Foundation 里——因为它们不适合单选格式,被归入 Chat Benchmark。
题目构造流程
-
问题 q: 用 GPT-4 根据任务描述 + 3 个示例生成多样化问题,人工审核后每个任务选出 50 种不同问法(目的:测指令跟随能力而非模板记忆)
-
选项 C: 三种来源
-
原数据集自带选项(如 AVQA)→ 直接复用
-
分类任务 → 从预定义类别池随机抽
-
其余 → GPT-4 生成 1 正确 + 3 干扰项(鼓励干扰项与正确答案相似,增加难度)
-
-
选项随机打乱以消除位置偏差
-
所有音频来自 dev/test 集,防止数据泄露
3.3 Chat Benchmark 详解
数据分布
| 音频类型 | 数据来源 | 数量 | 问题示例 |
|---|---|---|---|
| 语音 | Fisher, SpokenWOZ, IEMOCAP, Common Voice | 800 | ”第一位说话者是否还有更多问题?“ |
| 环境音 | Clotho | 400 | ”根据音频中的语音,你应该对布料做什么?“ |
| 音乐 | MusicCaps | 400 | ”150 词内论述这段音乐如何传达爱国与庄严感” |
| 混合(语音+环境音) | Common Voice + AudioCaps | 200 | ”二十多岁男性说话时伴随着什么声音?“ |
| 混合(语音+音乐) | Common Voice + MusicCaps | 200 | ”男性说话者音频背景中能听到什么旋律?“ |
音频混合策略 🔑 本文亮点
混合音频是 Chat Benchmark 区别于其他基准的关键创新——模拟真实场景中”语音叠加背景音乐/环境音”的复杂情况。
两步混合法:
-
响度控制(Loudness Control)
-
分别对两段音频施加不同增益(如语音 +3dB,音乐 -3dB)
-
记录 Louder 元信息:哪段音频更响
-
-
时间错位混合(Temporal Dislocation Mixing)
-
两段音频在时间轴上偏移后叠加
-
记录 Ahead 元信息:哪段先出现(meanwhile / before / after)
-
混合后的音频附带完整元信息(性别、年龄、转录、音乐描述 + Louder + Ahead),供评估框架使用。
开放式 QA 构造
-
收集每段音频的所有 ground truth 元信息(性别、年龄、情感、转录、语言、音乐描述、乐器等)——不用预训练模型提取,避免引入噪声
-
针对不同音频类型手工设计 GPT-4 prompt:
-
语音: 侧重感知 + 推理(如情感推断、说话人关系推测)
-
环境音: 侧重场景推理(“听到这个声音你应该做什么”)
-
音乐: 侧重创作(基于音乐写故事、评论)
-
-
GPT-4 生成 QA 对 → 自动过滤与音频无关的问题 → 人工全量审核
-
GPT-4 生成的答案作为评估的参考答案(不是 ground truth,而是评分锚点)
3.4 数据质量保障总结
-
问题多样性:Foundation 每个任务 50 种问法
-
选项质量:干扰项与正确答案高度相似
-
数据来源:全部 dev/test 集
-
双重过滤:GPT-4 自动 + 人工审核
4. 评估框架
4.1 核心设计理念
Important
生成式评估(Generative Evaluation): 所有模型必须直接生成回答(hypothesis),而不是比较不同选项的 perplexity。这更贴合 LALMs 的实际使用场景。
关键问题:GPT-4 无法直接处理音频输入。
解决方案:将音频的丰富文本元信息(转录、情感标签、性别、年龄、音乐描述等 ground truth 标注)喂给 GPT-4,代替实际音频。
4.2 Foundation 评估
模型输入:音频 + 单选题
模型输出:hypothesis(自由文本)
评估:GPT-4 判断 hypothesis 是否与 golden choice 一致 → 0/1 二元打分为什么不用精确匹配(Exact Matching)?
| 模型 | 精确匹配成功率 | GPT-4 对齐成功率 |
|---|---|---|
| BLSP | 100.0% | 100.0% |
| SALMONN | 97.3% | 100.0% |
| NExT-GPT | 98.1% | 100.0% |
| Qwen-Audio Turbo | 48.2% | 100.0% |
| Qwen-Audio-Chat | 30.7% | 100.0% |
| PandaGPT | 30.8% | 100.0% |
| Macaw-LLM | 0.1% | 100.0% |
| SpeechGPT | 0.0% | 100.0% |
不同模型输出格式差异极大:BLSP 直接输出 “B”,SpeechGPT 输出整段自然语言。精确匹配在很多模型上完全失效,GPT-4 对齐后全部 100%。
4.3 Chat 评估
Step 1: GPT-4 Generator 根据元信息 + 问题 → 生成参考答案
Step 2: GPT-4 Evaluator 根据元信息 + 问题 + 参考答案 + 模型假设 → 打 1-10 分
评分维度:有用性、相关性、准确性、全面性参考答案的角色: 不是 ground truth,而是评分锚点——稳定 GPT-4 的打分行为。
消除位置偏差: 交换 hypothesis 和 reference 的顺序打两次分 → 取平均。论文实验证实不做交换会产生明显偏差(hypothesis 在前时得分偏高)。
4.4 与人类评估的一致性
-
Foundation: GPT-4 Turbo 与人类判断一致性 98.2%(400 题,3 位英语母语者评估);GPT-3.5 Turbo 为 96.4%
-
Chat: 在 Qwen-Audio-Chat / SALMONN / BLSP / GPT-4 的两两比较中,GPT-4 与人类偏好一致性 >70%(200 题,3 位英语母语者)
-
按音频类型细分:Music 和 Mixed Audio 的一致性略高;Sound 和 Speech 略低(推测原因:Sound 类有更多情境性问题,Speech 类有更多推理题,评估难度更大)
4.5 Prompt 工程
论文在附录 C 中分享了调 prompt 的经验:
-
去掉评分维度描述(有用性、相关性等)→ 满分答案降到 8-9 分,错误答案升到 2-3 分 → 说明这些”冗余描述”其实帮助 GPT-4 校准评分尺度
-
调换信息顺序(如把音频描述移到问答之后)→ 评分崩坏,原本满分的答案只得 5 分 → prompt 对信息排列极度敏感
-
小的标点或语法错误不影响评分
5. 实验结果
5.1 评估模型
共 9 个模型 + 1 个级联基线:
-
多音频类型模型: SALMONN、Qwen-Audio-Chat、Qwen-Audio Turbo
-
语音专项模型: SpeechGPT、BLSP、LLaSM
-
多模态模型: PandaGPT、Macaw-LLM、NExT-GPT
-
级联基线: Whisper-large-v2 + GPT-4 Turbo(仅适用于语音任务)
所有模型使用最新公开 checkpoint、最大参数量、默认解码策略。
5.2 主要结果
| 模型 | Foundation 语音 | Foundation 环境音 | Foundation 音乐 | Foundation 平均 | Chat 语音 | Chat 环境音 | Chat 音乐 | Chat 混合 | Chat 平均 |
|---|---|---|---|---|---|---|---|---|---|
| Qwen-Audio Turbo | 63.4% | 61.0% | 48.9% | 57.8% | 7.04 | 6.59 | 5.98 | 5.77 | 6.34 |
| Qwen-Audio-Chat | 58.7% | 60.2% | 44.8% | 54.5% | 6.47 | 6.95 | 5.52 | 5.38 | 6.08 |
| SALMONN | 37.8% | 33.0% | 37.1% | 36.0% | 6.16 | 6.28 | 5.95 | 6.08 | 6.11 |
| PandaGPT | 39.0% | 43.6% | 38.1% | 40.2% | 3.58 | 5.46 | 5.06 | 2.93 | 4.25 |
| BLSP | 36.6% | 31.4% | 26.1% | 31.4% | 6.17 | 5.55 | 5.08 | 4.52 | 5.33 |
| NExT-GPT | 33.6% | 32.2% | 28.9% | 31.5% | 3.86 | 4.76 | 4.18 | 2.92 | 4.13 |
| Macaw-LLM | 32.2% | 30.1% | 29.7% | 30.7% | 0.97 | 1.01 | 0.91 | 1.00 | 1.01 |
| SpeechGPT | 34.3% | 27.5% | 28.1% | 30.0% | 1.57 | 0.95 | 0.95 | 1.14 | 1.15 |
| Whisper+GPT-4 | 53.6% | / | / | / | 7.54 | / | / | / | / |
参考基线:四选一随机准确率 25%,二选一(性别/合成检测)50%。接近这些数值意味着模型在该任务上几乎没有能力。
5.3 核心洞察
Important
洞察 1:音频理解 vs 指令跟随的”跷跷板”
Qwen-Audio Turbo 综合最强,但指令格式跟随弱(精确匹配仅 48.2%,常输出完整句子而非选项字母)。BLSP 格式跟随完美(100%),但音频理解差(Foundation 平均仅 31.4%)。现有模型还没能同时做好”听懂”和”听话”。
Important
洞察 2:端到端模型尚未超越级联方案
在语音相关的 Chat 任务上,Whisper+GPT-4 拿到最高分 7.54,超过所有端到端 LALM。这说明当前端到端模型在语音理解+文本生成的联合优化上还有很大空间。不过级联方案天然无法处理环境音和音乐。
Important
洞察 3:混合音频是最大难点
大部分模型在 Mixed Audio 上得分最低。SALMONN 是唯一在混合音频上表现相对突出的(Chat 6.08),可能得益于其同时训练了语音和音频理解能力。
Important
洞察 4:Foundation 和 Chat 排名不完全一致
SALMONN 的 Foundation 成绩平平(36%),但 Chat 排名第二(6.11)——说明基础单项能力和综合对话能力之间并非简单线性关系,可能涉及泛化、推理等高层能力。
6. 局限性
-
不支持多音频比较: 如评估两段音乐的连贯性、相似度
-
不覆盖多轮对话: 只测单轮 QA,不评估上下文跟踪能力
-
依赖 GPT-4 API: 评估成本较高,且如果 API 变动(涨价/关闭)需要寻找替代评估器
-
元信息替代音频的局限: GPT-4 评估基于文本元信息而非实际音频,可能遗漏某些音频细节