Important
为什么读这篇:任务是把副语言信息(paralinguistics)是怎么评测和分类的吃透——这是 audio LLM 路线上绕不开的评测侧知识。
动机
End-to-end 语音对话模型已经从 cascaded ASR→LLM→TTS,走到 reasoning-enhanced e2e SDM;但评测体系还停在“答案对不对 / 声学属性识别准不准”,没有跟上语音对话模型真正要具备的表达能力。本文把这个问题拆成 tripartite gap:
Gap 1 · Cognitive-Acoustic Alignment:推理对了,不等于听得懂。
现有 reasoning audio benchmark 多数只测答案正确性,没有评估模型能否把 复杂推理 用 自然口语 讲清楚;这篇把这个缺口标成 Cognitive-Acoustic Alignment,即“推理能力”和“可听懂的推理表达”之间的对齐问题。
Gap 2 · Colloquialism / Spoken listenability:口语表达是独立能力。
现有 benchmark 没把 “rigid written accuracy” 和 “spoken listenability” 分开评估,但 e2e SDM 相比 cascaded system 的关键差异,正是能不能把正确答案说得像人、自然、适合被听。
Paper 进一步把 colloquialism 拆成四个概念:lexical appropriateness(日常用词 + discourse markers)、linguistic naturalness(短句、省略、倒装等口语句法)、interactive rapport(反问、确认、建议引导对话)、emotional-contextual matching(情感语境匹配)。
Gap 3 · Paralinguistic fidelity:副语言信息评测不完整。
现有 benchmark 对 paralinguistics 的覆盖零散,要么只测少数属性,要么只测理解不测生成,要么缺少隐式多轮场景;WavBench 把 age / gender / accent / language / pitch / speed / volume / emotion / background audio / music 这 10 类信号统一纳入 paralinguistic fidelity 评测。
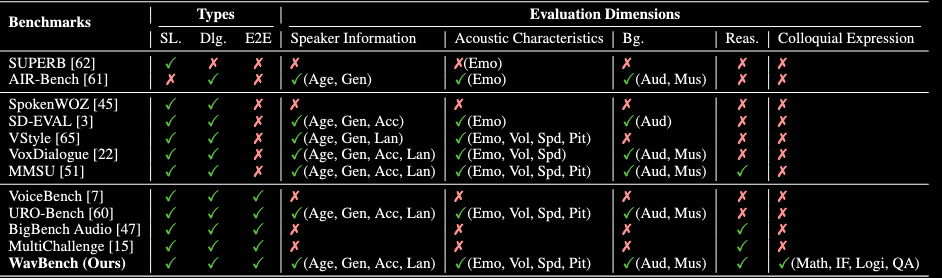
相关 Benchmark 缺陷梳理
一句话总括:前人 benchmark 分别测了 speech/audio understanding、任务型对话成功率、副语言理解、显式风格控制、e2e 内容正确性、audio reasoning correctness,但没有同时测 复杂推理是否能被自然说出来、回答是否具备 spoken listenability、以及副语言信息是否能在理解—生成—隐式多轮互动中保持一致。
| 类型划分 | Benchmark | 它如何 eval | WavBench 视角下的缺陷 |
|---|---|---|---|
| Speech representation / 基础语音理解 | SUPERB | 把 speech encoder 放到多个下游任务上测,如 ASR、phoneme recognition、speaker ID、emotion recognition;指标通常是 WER / PER / accuracy 等。 | 测的是语音表征,不是 spoken dialogue;不评估 e2e 对话输出,也不系统覆盖副语言生成。 |
| Audio-language understanding | AIR-Bench | 输入 speech / audio event / music,让模型做生成式音频理解问答,评估回答内容是否正确。 | 能测 audio comprehension,但主要停在理解端;没有把语音回答的口语可听性和声学生成质量作为核心指标。 |
| Task-oriented spoken dialogue | SpokenWOZ | 在任务型 spoken dialogue 中测系统是否完成用户目标,如订酒店、查餐馆;常看 task success、inform rate、response quality 等。 | 关注任务完成,不关注开放语音对话里的情绪、口语自然度和副语言互动。 |
| Paralinguistic understanding | SD-Eval | 构造带 emotion、accent、age、background sound 等因素的语音输入,让模型识别或回答相关属性。 | 主要测 input perception,即“听出副语言属性”;不充分测模型能否用合适副语言风格生成回答。 |
| Explicit voice style control | VStyle | 给模型显式 spoken instruction,如要求某种角色、语气或风格,评估生成语音是否遵循风格指令。 | 测显式风格控制,但真实对话常常是隐式情绪和语境;也没有测复杂推理时是否还能保持 listenability。 |
| Scenario-based paralinguistic understanding | VoxDialogue | 在更贴近 dialogue scenario 的语音数据中测 age、gender、accent、language、emotion、volume、speed、background audio / music 等属性理解。 | 副语言理解维度更全,但仍偏 understanding;没有真正评估 e2e speech output 的生成和互动能力。 |
| Massive spoken language understanding | MMSU | 基于语言学理论设计大量 spoken understanding tasks,覆盖 phonetics、semantics、paralinguistics 和 reasoning;模型听语音后输出文本答案或标签。 | 把 spoken understanding 做得很细,但仍停在 perception phase;不评估 spoken response generation 的自然度和副语言保真。 |
| E2E voice assistant content eval | VoiceBench | 让 voice assistant 接收语音输入并回答,主要评价回答是否正确、有用、安全。 | 开始测 e2e voice assistant,但重点仍是 content correctness;没有区分 written accuracy 和 spoken listenability。 |
| E2E spoken dialogue 综合评测 | URO-Bench | 面向 e2e SDM,覆盖 speaker information、acoustic characteristics、background sound 等,测模型在语音输入 / 输出场景下的综合表现。 | 声学互动覆盖较全,但缺少高难 reasoning 和 colloquial expression;没有测“复杂内容能不能自然说出来”。 |
| Audio reasoning benchmark | BigBench Audio | 把 Big-Bench / Big-Bench Hard 中适合音频化的 reasoning tasks 转成 audio input,模型听题作答,主要看最终答案是否正确。 | 把 speech 当成 text 的传输媒介;测 reasoning correctness,不测推理过程是否口语化、可听、降低 cognitive load。 |
| Multi-turn reasoning / instruction following | MultiChallenge | 测多轮对话中的 instruction following、context management、situational reasoning;迁移到 audio 后仍主要关注多轮任务是否答对、上下文是否跟住。 | 测多轮推理和上下文管理,但没有把语音输出的口语自然度和副语言匹配作为核心评价对象。 |
| WavBench 自己的位置 | WavBench | 用 Pro / Basic / Acoustic 三组评测分别测 reasoning + listenability、日常 colloquial expression、以及 explicit understanding / explicit generation / implicit interaction 中的 paralinguistic fidelity。 | 它试图补齐三件事:复杂推理要说得可听,普通回答要像人说话,副语言信息要能理解、生成并在隐式多轮中保持一致。 |
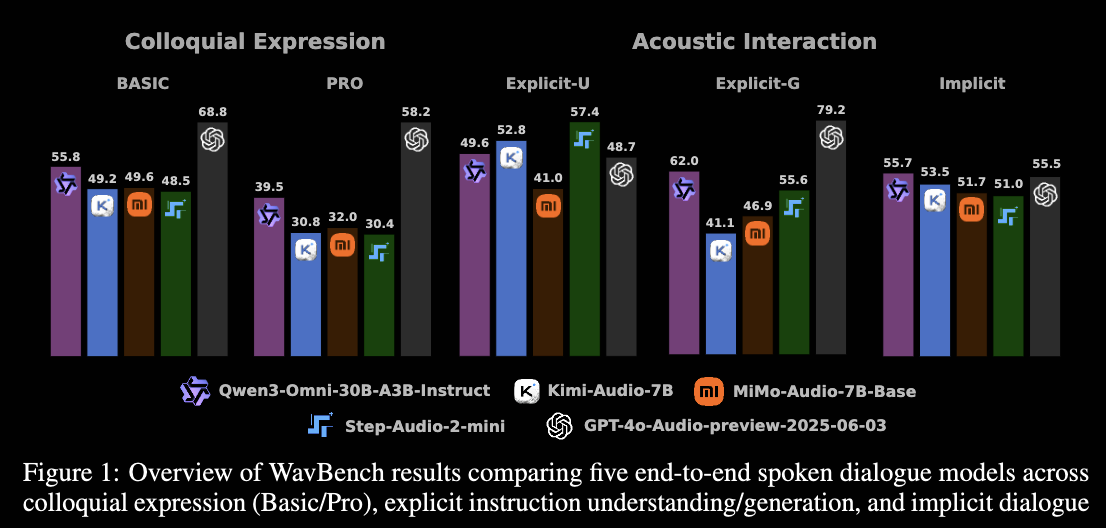
方法:评测能力分类
WavBench 的 method 不是提出新模型,而是设计一个 benchmark taxonomy:先定义要测哪些能力,再为每类能力构造对应 subset 和评分协议。
| 一级能力 | 能力含义 | Subset | 具体测什么 |
|---|---|---|---|
| Colloquial Expression Capability | 语义内容 + 口语可听性 | Basic subset | 日常难度任务,测模型是不是能把普通回答说得自然、亲切、像人说话,而不是像书面文本朗读。 |
| 语义内容 + 口语可听性 | Pro subset | 高认知负载任务,测复杂 reasoning、math、logic、code、instruction following 能不能被口语化讲清楚,让听者不费劲跟上。 | |
| Acoustic Interaction Capability | 副语言信息理解与生成 | Explicit Understanding | 显式问模型识别语音属性,比如 emotion、accent、age、gender、pitch、speed、volume、background audio / music 等。 |
| 副语言信息理解与生成 | Explicit Generation | 显式要求模型生成某种语音风格,比如开心语气、低音量、慢速、特定口音、背景音或音乐。 | |
| 副语言信息理解与生成 | Implicit Interaction | 不直接告诉模型情绪或声学条件,让模型从语音、场景和多轮上下文中隐式判断用户状态,并生成内容和风格都匹配的语音回应。 |
一句话概括:Basic / Pro 测“回答是否正确且适合被听”,Explicit-U / Explicit-G / Implicit 测“副语言信息能否被识别、生成,并在真实对话中自然使用”。
方法:数据构造
Benchmark 的数据构造要回答:测试样本从哪里来、怎么变成语音、怎么保证质量。WavBench 分两条 pipeline:
| 数据集部分 | 来源与构造流程 | 质量控制 |
|---|---|---|
| Colloquial Expression Set | 从 15 个开源文本数据集采样任务,覆盖 code、creative writing、instruction following、logic、math、common QA、safety 等认知域;再按难度拆成 Basic / Pro,并用 LLM 做 spoken adaptation,把书面题改写成适合语音对话的问题。 | 用 IndexTTS2 合成语音,再用 Whisper-Large-V3 做 ASR 检查;WER 过高的样本过滤掉,避免 TTS 读错导致评测污染。 |
| Acoustic Interaction Set | 围绕 10 类副语言属性构造:age、gender、accent、language、pitch、speed、volume、emotion、background audio、music;用 LLM 生成带场景的对话脚本,再用 TTS / 音频素材库合成目标声学条件。 | 用 Whisper-Large-V3 过滤转写错误,用 Emotion2Vec 等模型过滤情绪标签不准的样本,并辅以人工检查,确保声学属性和文本内容都可用。 |
一句话概括:Colloquial set 是“文本任务 → 口语化改写 → TTS 合成 → ASR 过滤”;Acoustic set 是“定义副语言属性 → 生成场景脚本 → 合成目标声音条件 → 自动模型 + 人工过滤”。
如何测试
模型测试要回答:被测模型吃什么输入、产出什么输出、不同 subset 怎么运行。WavBench 面向 e2e SDM,核心协议是 speech-in / speech-out。
| Subset | 输入 | 模型输出 | 测试目标 |
|---|---|---|---|
| Basic / Pro | 语音形式的问题或指令。 | 语音回答。 | 看模型是否既完成语义任务,又能把回答说得自然、口语化、适合被听。 |
| Explicit Understanding | 带有明确副语言属性的用户语音,并显式询问该属性。 | 属性标签。 | 看模型能否识别 emotion、accent、speed、volume、background audio / music 等语音属性。 |
| Explicit Generation | 显式风格控制指令,如要求某种情绪、语速、音量或口音。 | 带目标风格的语音回答。 | 看模型能否按要求生成匹配目标副语言属性的语音。 |
| Implicit Interaction | 不直接说明情绪或声学条件的语音对话场景。 | 内容和语气都应匹配场景的语音回应。 | 看模型能否从语音、语境和多轮上下文中隐式推断用户状态,并自然回应。 |
一句话概括:WavBench 的被测对象是端到端语音对话模型,但测试任务被拆成内容表达、属性理解、属性生成、隐式互动四种运行方式。
方法:打分与评价指标
打分部分是这篇最关键、也最容易被 challenge 的地方:WavBench 把不同 subset 映射到不同 metric。
| 评测部分 | 打分方式 | 分数含义 | 隐含假设 / 风险 |
|---|---|---|---|
| Basic / Pro | Gemini 3 Pro Preview 做 LLM-as-judge,使用 1 / 3 / 5 三档评分。 | 1 = 任务失败或答案错;3 = 答案对但书面僵硬;5 = 答案对且口语自然、适合被听。 | 隐含假设是 Gemini 能稳定判断语义正确性和 spoken listenability;三档评分更稳定,但牺牲细粒度差异。 |
| Explicit Understanding | 模型输出属性 label,与 ground truth label 对比,计算 accuracy。 | 直接衡量模型是否听出目标副语言属性。 | 相对干净,但依赖标签本身是否准确、属性边界是否清楚。 |
| Explicit Generation | 模型生成语音后,用 Gemini 3 Pro Preview 判断生成音频是否符合目标属性,再算 accuracy。 | 衡量模型是否能按显式指令生成指定情绪、语速、音量、口音等声学风格。 | 隐含假设是 Gemini 具备可靠音频副语言识别能力;judge bias 会直接影响分数。 |
| Implicit Interaction | 拆成 text/content score 和 audio/style score:一边评回答内容是否合理,一边评语音风格是否匹配隐式场景。 | 衡量模型是否能在真实对话里同时做到“说什么对”和“怎么说对”。 | 不是纯单一端到端总体分,而是分解式评价;优点是可解释,缺点是依赖 judge 对内容和音频风格的可靠判断。 |
一句话概括:Colloquial 表达用 1/3/5 区分 incorrect、correct-but-written、correct-and-spoken;
副语言理解用 label accuracy;
副语言生成和隐式互动高度依赖 Gemini 作为 multimodal audio judge。