Qwen Technical Report
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, Tianhang Zhu.
Qwen Team, Alibaba Group*
Abstract
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce QWEN the first installment of our large language model series. QWEN is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.
1
Contents
1 Introduction ….. 3
2 Pretraining ….. 4
2.1 Data ….. 4
2.2 Tokenization ….. 6
2.3 Architecture ….. 6
2.4 Training ….. 7
2.5 Context Length Extension ….. 7
2.6 Experimental Results ….. 8
3 Alignment ….. 9
3.1 Supervised Finetuning ….. 9
3.1.1 Data ….. 10
3.1.2 Training ….. 10
3.2 Reinforcement Learning from Human Feedback ….. 10
3.2.1 Reward Model ….. 10
3.2.2 Reinforcement Learning ….. 11
3.3 Automatic and Human Evaluation of Aligned Models ….. 11
3.4 Tool Use, Code Interpreter, and Agent ….. 13
4 Code-Qwen: Specialized Model for Coding ….. 16
4.1 Code Pretraining ….. 16
4.2 Code Supervised Fine-Tuning ….. 17
4.3 Evaluation ….. 17
5 Math-Qwen: Specialized Model for Mathematics Reasoning ….. 17
5.1 Training ….. 17
5.2 Evaluation ….. 20
6 Related Work ….. 20
6.1 Large Language Models ….. 20
6.2 Alignment ….. 20
6.3 Tool Use and Agents ….. 21
6.4 LLM for Coding ….. 21
6.5 LLM for Mathematics ….. 22
7 Conclusion ….. 22
A Appendix ….. 36
A. 1 More Training Details ….. 36
A.1.1 Data Format for Qwen-Chat ….. 36
A. 2 Evaluation ….. 36
A.2.1 Automatic Evaluation ….. 36
A.2.2 Human Evaluation ….. 40
A. 3 Analysis of Code Interpreter ….. 58
1 Introduction
Large language models (LLMs) (Radford et al., 2018, Devlin et al., 2018, Raffel et al., 2020; Brown et al., 2020; OpenAI, 2023; Chowdhery et al., 2022; Anil et al., 2023; Thoppilan et al., 2022; Touvron et al., 2023a b) have revolutionized the field of artificial intelligence (AI) by providing a powerful foundation for complex reasoning and problem-solving tasks. These models have the ability to compress vast knowledge into neural networks, making them incredibly versatile agents. With a chat interface, LLMs can perform tasks that were previously thought to be the exclusive domain of humans, especially those involving creativity and expertise (OpenAI, 2022; Ouyang et al., 2022; Anil et al., 2023, Google, 2023; Anthropic, 2023a b). They can engage in natural language conversations with humans, answering questions, providing information, and even generating creative content such as stories, poems, and music. This has led to the development of a wide range of applications, from chatbots and virtual assistants to language translation and summarization tools.
LLMs are not just limited to language tasks. They can also function as a generalist agent (Reed et al., 2022; Bai et al., 2022a; Wang et al., 2023a, AutoGPT, 2023; Hong et al., 2023), collaborating with external systems, tools, and models to achieve the objectives set by humans. For example, LLMs can understand multimodal instructions (OpenAI, 2023; Bai et al., 2023; Liu et al., 2023a; Ye et al., 2023, Dai et al., 2023, Peng et al., 2023b), execute code (Chen et al., 2021; Zheng et al., 2023; Li et al., 2023d), use tools (Schick et al., 2023, LangChain, Inc., 2023; AutoGPT, 2023), and more. This opens up a whole new world of possibilities for AI applications, from autonomous vehicles and robotics to healthcare and finance. As these models continue to evolve and improve, we can expect to see even more innovative and exciting applications in the years to come. Whether it’s helping us solve complex problems, creating new forms of entertainment, or transforming the way we live and work, LLMs are poised to play a central role in shaping the future of AI.
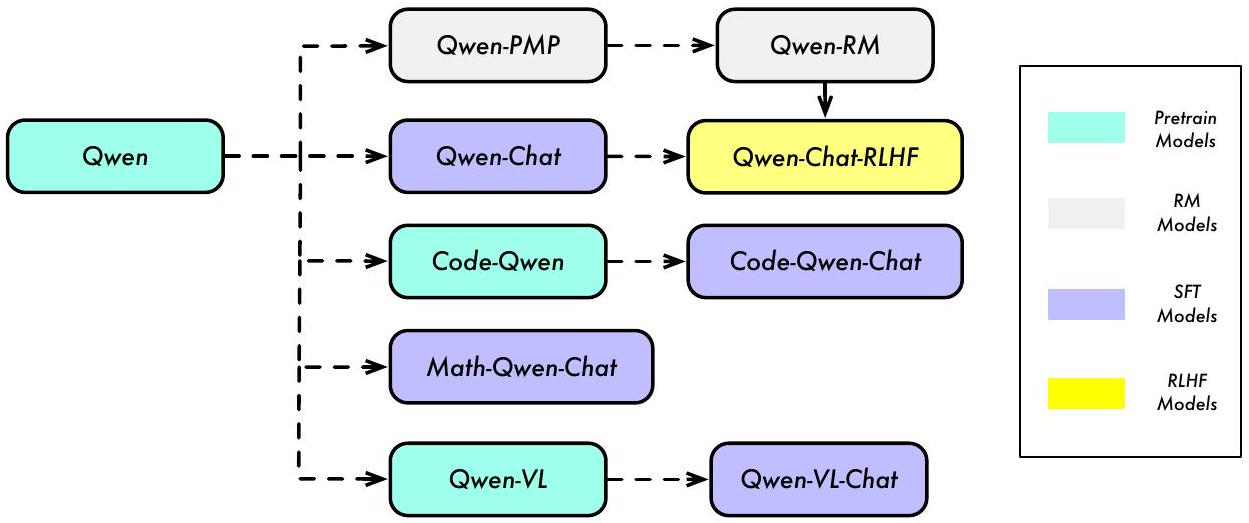
Figure 1: Model Lineage of the Qwen Series. We have pretrained the language models, namely QWEN, on massive datasets containing trillions of tokens. We then use SFT and RLHF to align Qwen to human preference and thus we have Qwen-Chat and specifically its improved version Qwen-Chat-RLHF. Additionally, we also develop specialized models for coding and mathematics, such as Code-Qwen, Code-Qwen-Chat, and Math-Qwen-Chat based on Qwen with similar techniques. Note that we previously released the multimodal LLM, QWEN-VL and Qwen-VLChat (Bai et al., 2023), which are also based on our Qwen base models.
Despite their impressive capabilities, LLMs are often criticized for their lack of reproducibility, steerability, and accessibility to service providers. In this work, we are pleased to present and release the initial version of our LLM series, Qwen. Qwen is a moniker that derives from the Chinese phrase Qianwen, which translates to “thousands of prompts” and conveys the notion of embracing a wide range of inquiries. QWEN is a comprehensive language model series that encompasses distinct models with varying parameter counts. The model series include the base pretrained language models, chat models finetuned with human alignment techniques, i.e., supervised finetuning (SFT), reinforcement learning with human feedback (RLHF), etc., as well as specialized models in coding and math. The details are outlined below:
-
The base language models, namely QWEN, have undergone extensive training using up to 3 trillion tokens of diverse texts and codes, encompassing a wide range of areas. These models have consistently demonstrated superior performance across a multitude of downstream tasks, even when compared to their more significantly larger counterparts.
-
The QWEN-CHAT models have been carefully finetuned on a curated dataset relevant to task performing, chat, tool use, agent, safety, etc. The benchmark evaluation demonstrates that the SFT models can achieve superior performance. Furthermore, we have trained reward models to mimic human preference and applied them in RLHF for chat models that can produce responses preferred by humans. Through the human evaluation of a challenging test, we find that Qwen-Chat models trained with RLHF are highly competitive, still falling behind GPT-4 on our benchmark.
-
In addition, we present specialized models called Code-Qwen, which includes Code-Qwen-7B and Code-Qwen-14B, as well as their chat models, Code-Qwen-14BChat and Code-Qwen-7B-Chat. Specifically, Code-Qwen has been pre-trained on extensive datasets of code and further fine-tuned to handle conversations related to code generation, debugging, and interpretation. The results of experiments conducted on benchmark datasets, such as HumanEval (Chen et al., 2021), MBPP (Austin et al., 2021), and HumanEvalPack (Muennighoff et al., 2023), demonstrate the high level of proficiency of Code-Qwen in code understanding and generation.
-
This research additionally introduces Math-Qwen-Chat specifically designed to tackle mathematical problems. Our results show that both Math-Qwen-7B-Chat and Math-QWEN-14B-CHAT outperform open-sourced models in the same sizes with large margins and are approaching GPT-3.5 on math-related benchmark datasets such as GSM8K (Cobbe et al., 2021) and MATH (Hendrycks et al., 2021).
-
Besides, we have open-sourced QWEN-VL and QWEN-VL-CHAT, which have the versatile ability to comprehend visual and language instructions. These models outperform the current open-source vision-language models across various evaluation benchmarks and support text recognition and visual grounding in both Chinese and English languages. Moreover, these models enable multi-image conversations and storytelling. Further details can be found in Bai et al. (2023).
Now, we officially open-source the 14B-parameter and 7B-parameter base pretrained models QWEN and aligned chat models QWEN-CHAT This release aims at providing more comprehensive and powerful LLMs at developer- or application-friendly scales.
The structure of this report is as follows: Section 2 describes our approach to pretraining and results of Qwen. Section 3 covers our methodology for alignment and reports the results of both automatic evaluation and human evaluation. Additionally, this section describes details about our efforts in building chat models capable of tool use, code interpreter, and agent. In Sections 4 and [5] we delve into specialized models of coding and math and their performance. Section 6 provides an overview of relevant related work, and Section 7 concludes this paper and points out our future work.
2 Pretraining
The pretraining stage involves learning vast amount of data to acquire a comprehensive understanding of the world and its various complexities. This includes not only basic language capabilities but also advanced skills such as arithmetic, coding, and logical reasoning. In this section, we introduce the data, the model design and scaling, as well as the comprehensive evaluation results on benchmark datasets.
2.1 DATA
The size of data has proven to be a crucial factor in developing a robust large language model, as highlighted in previous research (Hoffmann et al., 2022; Touvron et al., 2023b). To create an effective pretraining dataset, it is essential to ensure that the data are diverse and cover a wide range
2
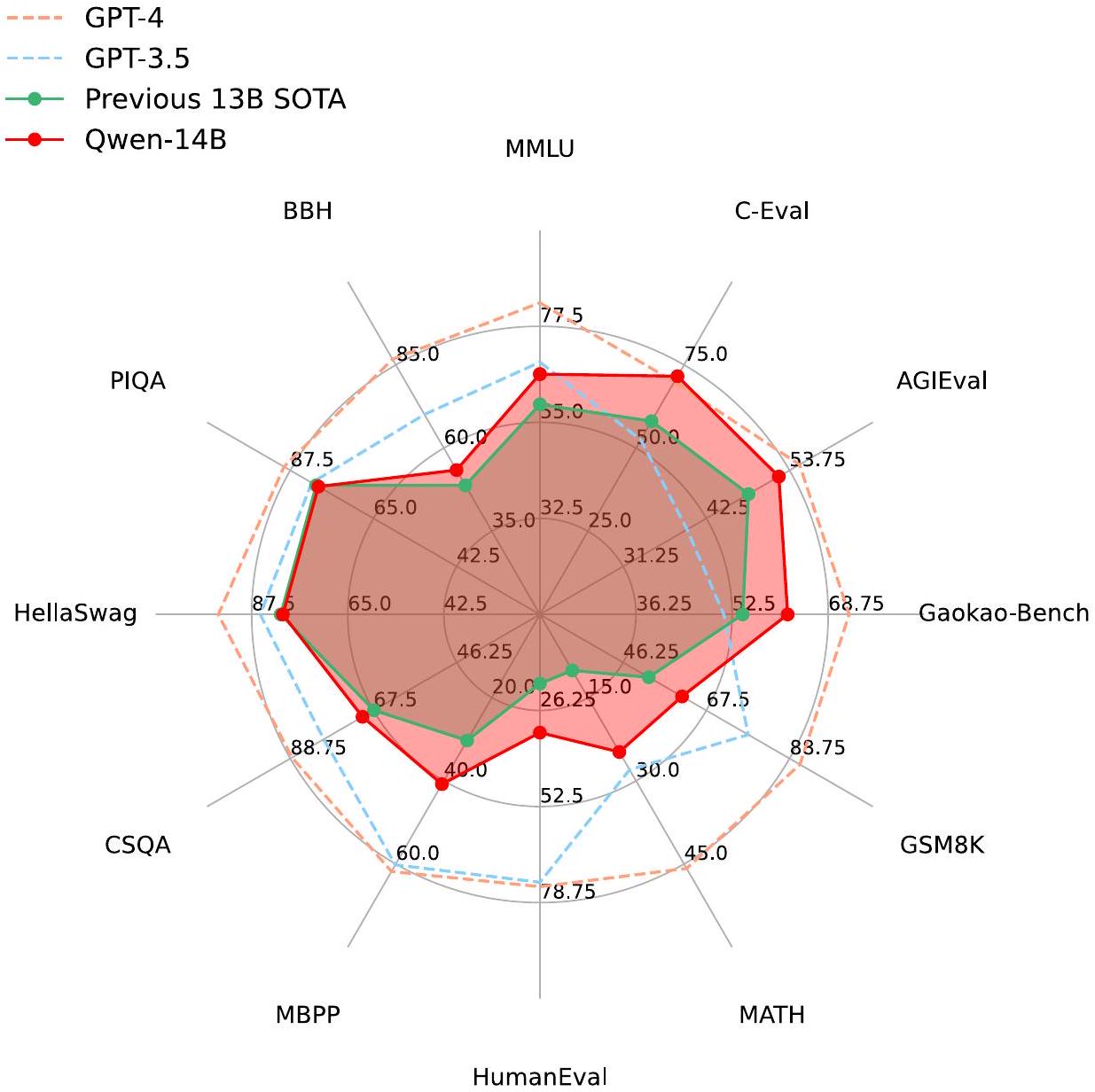
Figure 2: Performance of GPT-4, GPT-3.5, the previous 13B SOTA, as well as Qwen-14B. We demonstrate the results on 12 datasets covering multiple domains, including language understanding, knowledge, reasoning, etc. QWEN significantly outperforms the previous SOTA of similar model sizes, but still lag behind both GPT-3.5 and GPT-4.
of types, domains, and tasks. Our dataset is designed to meet these requirements and includes public web documents, encyclopedia, books, codes, etc. Additionally, our dataset is multilingual, with a significant portion of the data being in English and Chinese.
To ensure the quality of our pretraining data, we have developed a comprehensive data preprocessing procedure. For public web data, we extract text from HTML and use language identification tools to determine the language. To increase the diversity of our data, we employ deduplication techniques, including exact-match deduplication after normalization and fuzzy deduplication using MinHash and LSH algorithms. To filter out low-quality data, we employ a combination of rule-based and machine-learning-based methods. Specifically, we use multiple models to score the content, including language models, text-quality scoring models, and models for identifying potentially offensive or inappropriate content. We also manually sample texts from various sources and review them to ensure their quality. To further enhance the quality of our data, we selectively up-sample data from certain sources, to ensure that our models are trained on a diverse range of high-quality content. In recent studies (Zeng et al., 2022; Aribandi et al., 2021; Raffel et al., 2020), it has been demonstrated that pretraining language models with multi-task instructions can enhance their zero-shot and few-shot performance. To further enhance the performance of our model, we have incorporated high-quality instruction data into our pretraining process. To safeguard the integrity of our benchmark assessment, we have adopted a similar approach as Brown et al. (2020) and meticulously eliminated any instruction
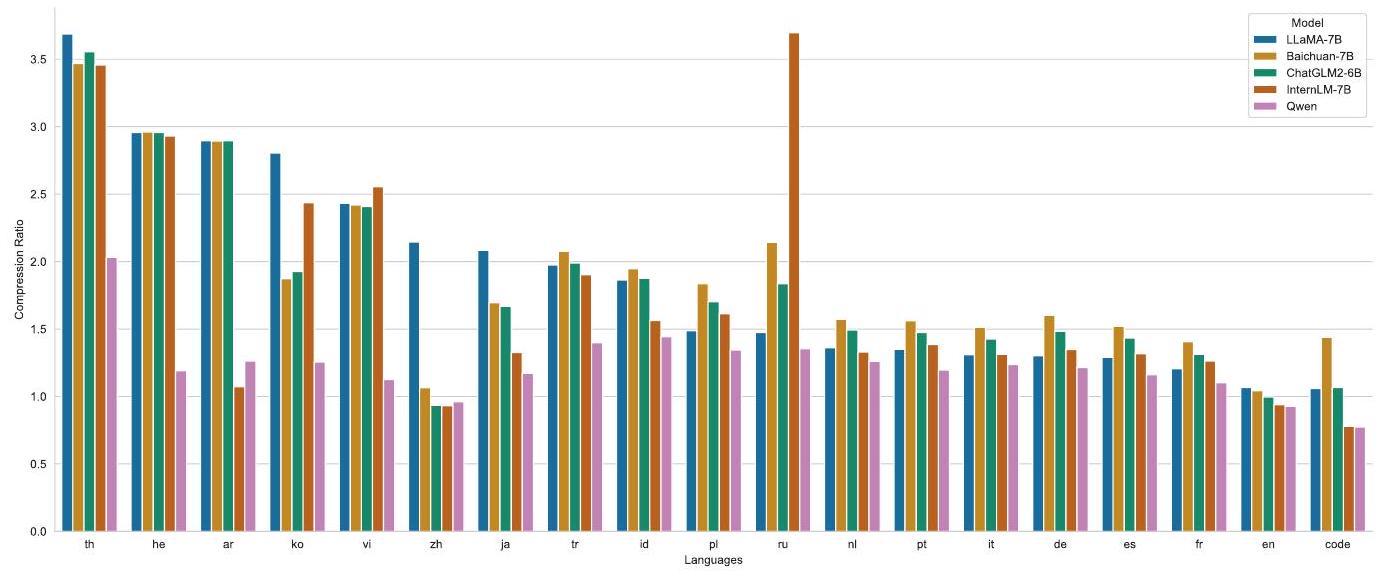
Figure 3: Encoding compression rates of different models. We randomly selected 1 million document corpora of each language to test and compare the encoding compression rates of different models (with XLM-R (Conneau et al., 2019), which supports 100 languages, as the base value 1, not shown in the figure). As can be seen, while ensuring the efficient decoding of Chinese, English, and code, QWEN also achieves a high compression rate for many other languages (such as th, he, ar, ko, vi, ja, tr, id, pl, ru, nl, pt, it, de, es, fr, etc.), equipping the model with strong scalability as well as high training and inference efficiency in these languages.
samples that exhibit a 13-gram overlap with any data present in the test sets utilized in our evaluation. Given the large number of downstream tasks, it is not feasible to repeat this filtering process for all tasks. Instead, we have made sure that the instruction data for the reported tasks have undergone our filtering process to ensure their accuracy and reliability. Finally, we have built a dataset of up to 3 trillion tokens.
2.2 Tokenization
The design of vocabulary significantly impacts the training efficiency and the downstream task performance. In this study, we utilize byte pair encoding (BPE) as our tokenization method, following GPT-3.5 and GPT-4. We start with the open-source fast BPE tokenizer, tiktoken (Jain, 2022), and select the vocabulary cl100k base as our starting point. To enhance the performance of our model on multilingual downstream tasks, particularly in Chinese, we augment the vocabulary with commonly used Chinese characters and words, as well as those in other languages. Also, following Touvron et al. (2023a b), we have split numbers into single digits. The final vocabulary size is approximately 152 K .
The performance of the QWEN tokenizer in terms of compression is depicted in Figure 3. In this comparison, we have evaluated Qwen against several other tokenizers, including XLM-R (Conneau et al., 2019), LLaMA (Touvron et al., 2023a), Baichuan (Inc., 2023a), and InternLM (InternLM Team. 2023). Our findings reveal that QWEN achieves higher compression efficiency than its competitors in most languages. This implies that the cost of serving can be significantly reduced since a smaller number of tokens from QWEN can convey more information than its competitors. Furthermore, we have conducted preliminary experiments to ensure that scaling the vocabulary size of QWEN does not negatively impact the downstream performance of the pretrained model. Despite the increase in vocabulary size, our experiments have shown that QWEN maintains its performance levels in downstream evaluation.
2.3 Architecture
QWEN is designed using a modified version of the Transformer architecture. Specifically, we have adopted the recent open-source approach of training large language models, LLaMA (Touvron et al.) 2023a), which is widely regarded as the top open-source LLM. Our modifications to the architecture include:
Table 1: Model sizes, architectures, and optimization hyper-parameters.
| 参数量 | Hidden size | 注意力头数 | 层数 | 学习率 | Batch size | 训练 Token 数 |
|---|---|---|---|---|---|---|
| 1.8 B | 2048 | 16 | 24 | 3.0 × 10⁻⁴ | 4 M | 2.2 T |
| 7 B | 4096 | 32 | 32 | 3.0 × 10⁻⁴ | 4 M | 2.4 T |
| 14 B | 5120 | 40 | 40 | 3.0 × 10⁻⁴ | 4 M | 3.0 T |
-
Embedding and output projection. Based on preliminary experimental findings, we have opted for the untied embedding approach instead of tying the weights of input embedding and output projection. This decision was made in order to achieve better performance with the price of memory costs.
-
Positional embedding. We have chosen RoPE (Rotary Positional Embedding) (Su et al. 2021) as our preferred option for incorporating positional information into our model. RoPE has been widely adopted and has demonstrated success in contemporary large language models, notably PaLM (Chowdhery et al., 2022; Anil et al., 2023) and LLaMA (Touvron et al., 2023a b). In particular, we have opted to use FP32 precision for the inverse frequency matrix, rather than BF16 or FP16, in order to prioritize model performance and achieve higher accuracy.
-
Bias. For most layers, we remove biases following Chowdhery et al. (2022), but we add biases in the QKV layer of attention to enhance the extrapolation ability of the model (Su. 2023b).
-
Pre-Norm & RMSNorm. In modern Transformer models, pre-normalization is the most widely used approach, which has been shown to improve training stability compared to post-normalization. Recent research has suggested alternative methods for better training stability, which we plan to explore in future versions of our model. Additionally, we have replaced the traditional layer normalization technique described in (Ba et al., 2016) with RMSNorm (Jiang et al., 2023). This change has resulted in equivalent performance while also improving efficiency.
-
Activation function. We have selected SwiGLU (Shazeer, 2020) as our activation function, a combination of Swish (Ramachandran et al., 2017) and Gated Linear Unit (Dauphin et al., 2017). Our initial experiments have shown that activation functions based on GLU generally outperform other baseline options, such as GeLU (Hendrycks & Gimpel, 2016). As is common practice in previous research, we have reduced the dimension of the feed-forward network (FFN) from 4 times the hidden size to of the hidden size.
2.4 Training
2.5 Context Length Extension
Transformer models have a significant limitation in terms of the context length for their attention mechanism. As the context length increases, the quadratic-complexity computation leads to a drastic increase in both computation and memory costs. In this work, we have implemented simple training-free techniques that are solely applied during inference to extend the context length of the model. One of the key techniques we have used is NTK-aware interpolation (bloc97, 2023).
Table 2: Overall performance on widely-used benchmarks compared to open-source base models. Our largest QWEN model with 14 billion parameters outperforms previous 13B SoTA models on all datasets.
| Model | Params | MMLU 5-shot | C-Eval 5-shot | GSM8K 8-shot | MATH 4-shot | HumanEval 0-shot | MBPP 3-shot | BBH 3-shot |
| :— | :— | :— | :— | :— | :— | :— | :— | :— |
| MPT | 7B 30B | 30.8 47.9 | 23.5 - | 9.1 15.2 | 3.0 3.1 | 18.3 25.0 | 22.8 32.8 | 35.6 38.0 |
| Falcon | 7B 40B | 27.8 57.0 | - | 6.8 19.6 | 2.3 5.5 | – | 11.2 29.8 | 28.0 37.1 |
| ChatGLM2 | 6B | 47.9 | 51.7 | 32.4 | 6.5 | - | - | 33.7 |
| InternLM | 7B 20B | 51.0 62.1 | 53.4 58.8 | 31.2 52.6 | 6.3 7.9 | 10.4 25.6 | 14.0 35.6 | 37.0 52.5 |
| Baichuan2 | 7B 13B | 54.7 59.5 | 56.3 59.0 | 24.6 52.8 | 5.6 10.1 | 18.3 17.1 | 24.2 30.2 | 41.6 49.0 |
| LLaMA | 7B 13B 33B 65B | 35.6 47.7 58.7 63.7 | 27.3 31.8 37.5 40.4 | 11.0 20.3 42.3 54.4 | 2.9 4.2 7.1 10.6 | 12.8 15.8 21.7 23.7 | 17.7 22.0 30.2 37.7 | 33.5 37.9 50.0 58.4 |
| Llama 2 | 7B 13 B 34B 70 B | 46.8 55.0 62.6 69.8 | 32.5 41.4 50.1 | 16.7 29.6 42.2 63.3 | 3.3 5.0 6.2 13.5 | 12.8 18.9 22.6 29.9 | 20.8 30.3 33.0 45.0 | 38.2 45.6 44.1 64.9 |
| StableBeluga2 | 70B | 68.6 | 51.4 | 69.6 | 14.6 | 28.0 | 11.4 | 69.3 |
| Qwen | 1.8 B | 44.6 | 54.7 | 21.2 | 5.6 | 17.1 | 14.8 | 28.2 |
| | 14B | 58.2 | 63.5 | 51.7 | 11.6 | 29.9 | 40.8 | 45.0 |
Unlike position interpolation (PI) (Chen et al., 2023a) which scales each dimension of RoPE equally, adjusts the base of RoPE to prevent the loss of high-frequency information in a training-free manner. To further improve performance, we have also implemented a trivial extension called dynamic NTK-aware interpolation, which is later formally discussed in (Peng et al. 2023a). It dynamically changes the scale by chunks, avoiding severe performance degradation. These techniques allow us to effectively extend the context length of Transformer models without compromising their computational efficiency or accuracy.
Qwen additionally incorporates two attention mechanisms: LogN-Scaling (Chiang & Cholak, 2022, Su, 2023a) and window attention (Beltagy et al., 2020). LogN-Scaling rescales the dot product of the query and value by a factor that depends on the ratio of the context length to the training length, ensuring that the entropy of the attention value remains stable as the context length grows. Window attention restricts the attention to a limited context window, preventing the model from attending to tokens that are too far away.
We also observed that the long-context modeling ability of our model varies across layers, with lower layers being more sensitive in context length extension compared to the higher layers. To leverage this observation, we assign different window sizes to each layer, using shorter windows for lower layers and longer windows for higher layers.
2.6 Experimental Results
To evaluate the zero-shot and few-shot learning capabilities of our models, we conduct a thorough benchmark assessment using a series of datasets. We compare Qwen with the most recent open-source base models, including LLaMA (Touvron et al., 2023a), Llama 2 (Touvron et al., 2023b), MPT (Mosaic ML, 2023), Falcon (Almazrouei et al., 2023), Baichuan2 (Yang et al., 2023), ChatGLM2 (ChatGLM2 Team, 2023), InternLM (InternLM Team, 2023), XVERSE (Inc., 2023b), and StableBeluga2 (Stability AI, 2023). Our evaluation covers a total of 7 popular benchmarks,
Table 3: Results of Qwen on long-context inference using various techniques. Our experimental findings reveal that the application of our crucial techniques enables the model to consistently achieve low perplexity as the context length increases. This suggests that these techniques play a significant role in enhancing the model’s ability to comprehend and generate lengthy texts.
| Model | Sequence Length | | | | |
| :— | :— | :— | :— | :— | :— |
| | 1024 | 2048 | 4096 | 8192 | 16384 |
| Qwen-7B | 4.23 | 3.78 | 39.35 | 469.81 | 2645.09 |
| + dynamic_ntk | 4.23 | 3.78 | 3.59 | 3.66 | 5.71 |
| + dynamic_ntk + logn | 4.23 | 3.78 | 3.58 | 3.56 | 4.62 |
| + dynamic_ntk + logn + window_attn | 4.23 | 3.78 | 3.58 | 3.49 | 4.32 |
| Qwen-14B | - | 3.46 | 22.79 | 334.65 | 3168.35 |
| + dynamic_ntk + logn + window_attn | - | 3.46 | 3.29 | 3.18 | 3.42 |
which are MMLU (5-shot) (Hendrycks et al., 2020), C-Eval (5-shot) (Huang et al., 2023), GSM8K (8-shot) (Cobbe et al., 2021), MATH (4-shot) (Hendrycks et al., 2021), HumanEval (0-shot) (Chen et al., 2021), MBPP (0-shot) (Austin et al., 2021), and BBH (Big Bench Hard) (3 shot) (Suzgun et al., 2022). We aim to provide a comprehensive summary of the overall performance of our models across these benchmarks.
In this evaluation, we focus on the base language models without alignment and collect the baselines’ best scores from their official results and OpenCompass (OpenCompass Team, 2023). The results are presented in Table 2.
Our experimental results demonstrate that the three QWEN models exhibit exceptional performance across all downstream tasks. It is worth noting that even the larger models, such as LLaMA2-70B, are outperformed by QWEN-14B in 3 tasks. QWEN-7B also performs admirably, surpassing LLaMA213 B and achieving comparable results to Baichuan2-13B. Notably, despite having a relatively small number of parameters, QWEN-1.8B is capable of competitive performance on certain tasks and even outperforms larger models in some instances. The findings highlight the impressive capabilities of the Qwen models, particularly Qwen-14B, and suggest that smaller models, such as Qwen-1.8B, can still achieve strong performance in certain applications.
To evaluate the effectiveness of context length extension, Table 3 presents the test results on arXi、 in terms of perplexity (PPL). These results demonstrate that by combining NTK-aware interpolation, LogN-Scaling, and layer-wise window assignment, we can effectively maintain the performance of our models in the context of over 8192 tokens.
3 Alignment
Pretrained large language models have been found to be not aligned with human behavior, making them unsuitable for serving as AI assistants in most cases. Recent research has shown that the use of alignment techniques, such as supervised finetuning (SFT) and reinforcement learning from human feedback (RLHF), can significantly improve the ability of language models to engage in natural conversation. In this section, we will delve into the details of how QWEN models have been trained using SFT and RLHF, and evaluate their performance in the context of chat-based assistance.
3.1 Supervised Finetuning
To gain an understanding of human behavior, the initial step is to carry out SFT, which finetunes a pretrained LLM on chat-style data, including both queries and responses. In the following sections, we will delve into the details of data construction and training methods.
3.1.1 DATA
To enhance the capabilities of our supervised finetuning datasets, we have annotated conversations in multiple styles. While conventional datasets (Wei et al., 2022a) contain a vast amount of data prompted with questions, instructions, and answers in natural language, our approach takes it a step further by annotating human-style conversations. This practice, inspired by Ouyang et al. (2022), aims at improving the model’s helpfulness by focusing on natural language generation for diverse tasks. To ensure the model’s ability to generalize to a wide range of scenarios, we specifically excluded data formatted in prompt templates that could potentially limit its capabilities. Furthermore, we have prioritized the safety of the language model by annotating data related to safety concerns such as violence, bias, and pornography.
In addition to data quality, we have observed that the training method can significantly impact the final performance of the model. To achieve this, we utilized the ChatML-style format (OpenAI, 2022), which is a versatile meta language capable of describing both the metadata (such as roles) and the content of a turn. This format enables the model to effectively distinguish between various types of information, including system setup, user inputs, and assistant outputs, among others. By leveraging this approach, we can enhance the model’s ability to accurately process and analyze complex conversational data.
3.1.2 Training
Consistent with pretraining, we also apply next-token prediction as the training task for SFT. We apply the loss masks for the system and user inputs. More details are demonstrated in Section A.1.1.
The model’s training process utilizes the AdamW optimizer, with the following hyperparameters: set to set to 0.95 , and set to . The sequence length is limited to 2048 , and the batch size is 128 . The model undergoes a total of 4000 steps, with the learning rate gradually increased over the first 1430 steps, reaching a peak of . To prevent overfitting, weight decay is applied with a value of 0.1 , dropout is set to 0.1 , and gradient clipping is enforced with a limit of 1.0 .
3.2 Reinforcement Learning from Human Feedback
While SFT has proven to be effective, we acknowledge that its generalization and creativity capabilities may be limited, and it is prone to overfitting. To address this issue, we have implemented Reinforcement Learning from Human Feedback (RLHF) to further align SFT models with human preferences, following the approaches of Ouyang et al. (2022); Christiano et al. (2017). This process involves training a reward model and using Proximal Policy Optimization (PPO) (Schulman et al., 2017) to conduct policy training.
3.2.1 Reward Model
To create a successful reward model, like building a large language model (LLM), it is crucial to first undergo pretraining and then finetuning. This pretraining process, also known as preference model pretraining (PMP) (Bai et al., 2022b), necessitates a vast dataset of comparison data. This dataset consists of sample pairs, each containing two distinct responses for a single query and their corresponding preferences. Similarly, finetuning is also conducted on this type of comparison data, but with a higher quality due to the presence of quality annotations.
During the fine-tuning phase, we gather a variety of prompts and adjust the reward model based on human feedback for responses from the QWEN models. To ensure the diversity and complexity of user prompts are properly taken into account, we have created a classification system with around 6600 detailed tags and implemented a balanced sampling algorithm that considers both diversity and complexity when selecting prompts for annotation by the reward model (Lu et al., 2023). To generate a wide range of responses, we have utilized QWEN models of different sizes and sampling strategies, as diverse responses can help reduce annotation difficulties and enhance the performance of the reward model. These responses are then evaluated by annotators following a standard annotation guideline, and comparison pairs are formed based on their scores.
In creating the reward model, we utilize the same-sized pre-trained language model QWEN to initiate the process. It is important to mention that we have incorporated a pooling layer into the original
Table 4: Test Accuracy of QWEN preference model pretraining (PMP) and reward model (RM) on diverse human preference benchmark datasets.
| Dataset | QweN
Helpful-base | QWEN
Helpful-online | Anthropic
Helpful-base | Anthropic
Helpful-online | OpenAI
Summ. | Stanford
SHP | OpenAI
PRM800K |
| :— | :—: | :—: | :—: | :—: | :—: | :—: | :—: |
| PMP | 62.68 | 61.62 | 76.52 | 65.43 | 69.60 | 60.05 | 70.59 |
| RM | 74.78 | 69.71 | 73.98 | 64.57 | 69.99 | 60.10 | 70.52 |
QWEN model to extract the reward for a sentence based on a specific end token. The learning rate for this process has been set to a constant value of , and the batch size is 64 . Additionally, the sequence length is set to 2048, and the training process lasts for a single epoch.
We adopted the accuracy on the test dataset as an important but not exclusive evaluation metric for the reward model. In Table 4, we report the test pairwise accuracy of PMP and reward models on diverse human preference benchmark datasets (Bai et al., 2022b, Stiennon et al., 2020, Ethayarajh et al., 2022, Lightman et al., 2023). Specifically, Qwen Helpful-base and Qwen Helpful-online are our proprietary datasets. The responses in Qwen Helpful-base are generated from Qwen without RLHF, whereas Qwen Helpful-online includes responses from Qwen with RLHF. The results show that the PMP model demonstrates high generalization capabilities on out-of-distribution data, and the reward model demonstrates significant improvement on our QWEN reward datasets.
3.2.2 Reinforcement Learning
Our Proximal Policy Optimization (PPO) process involves four models: the policy model, value model, reference model, and reward model. Before starting the PPO procedure, we pause the policy model’s updates and focus solely on updating the value model for 50 steps. This approach ensures that the value model can adapt to different reward models effectively.
During the PPO operation, we use a strategy of sampling two responses for each query simultaneously. This strategy has proven to be more effective based on our internal benchmarking evaluations. We set the KL divergence coefficient to 0.04 and normalize the reward based on the running mean.
The policy and value models have learning rates of and , respectively. To enhance training stability, we utilize value loss clipping with a clip value of 0.15 . For inference, the policy top-p is set to 0.9 . Our findings indicate that although the entropy is slightly lower than when top-p is set to 1.0 , there is a faster increase in reward, ultimately resulting in consistently higher evaluation rewards under similar conditions.
Additionally, we have implemented a pretrained gradient to mitigate the alignment tax. Empirical findings indicate that, with this specific reward model, the KL penalty is adequately robust to counteract the alignment tax in benchmarks that are not strictly code or math in nature, such as those that test common sense knowledge and reading comprehension. It is imperative to utilize a significantly larger volume of the pretrained data in comparison to the PPO data to ensure the effectiveness of the pretrained gradient. Additionally, our empirical study suggests that an overly large value for this coefficient can considerably impede the alignment to the reward model, eventually compromising the ultimate alignment, while an overly small value would only have a marginal effect on alignment tax reduction.
3.3 Automatic and Human Evaluation of Aligned Models
To showcase the effectiveness of our aligned models, we conduct a comparison with other aligned models on well-established benchmarks, including MMLU (Hendrycks et al., 2020), C-Eval (Huang et al., 2023), GSM8K (Cobbe et al., 2021), HumanEval (Chen et al., 2021), and BBH (Suzgun et al., 2022). Besides the widely used few-shot setting, we test our aligned models in the zero-shot setting to demonstrate how well the models follow instructions. The prompt in a zero-shot setting consists of an instruction and a question without any previous examples in the context. The results of the baselines are collected from their official reports and OpenCompass (OpenCompass Team, 2023).
The results in Table 5 demonstrate the effectiveness of our aligned models in understanding human instructions and generating appropriate responses. QWEN-14B-Chat outperforms all other models
Table 5: Performance of aligned models on widely-used benchmarks. We report both zero-shot and few-shot performance of the models.
| Model | Params | MMLU 0-shot / 5-shot | C-Eval 0-shot / 5-shot | GSM8K 0-shot / 8-shot | HumanEval 0-shot | BBH 0-shot / 3-shot |
| :— | :— | :— | :— | :— | :— | :— |
| Proprietary models | | | | | | |
| GPT-3.5 | - | - / 69.1 | - / 52.5 | - / 78.2 | 73.2 | - / 70.1 |
| GPT-4 | - | - / 83.0 | - / 69.9 | - / 91.4 | 86.6 | - / 86.7 |
| Open-source models | | | | | | |
| ChatGLM2 | 6B | 45.5 / 46.0 | 50.1 / 52.6 | - / 28.8 | 11.0 | - / 32.7 |
| InternLM-Chat | 7B | - / 51.1 | - / 53.6 | - / 33.0 | 14.6 | - / 32.5 |
| Baichuan2-Chat | 7B | - / 52.9 | - / 55.6 | - / 32.8 | 13.4 | - / 35.8 |
| | 13B | - / 57.3 | - / 56.7 | - / 55.3 | 17.7 | - / 49.9 |
| Llama 2-Chat | 7B | - / 46.2 | - / 31.9 | - / 26.3 | 12.2 | - / 35.6 |
| | 13 B | - / 54.6 | - / 36.2 | - / 37.1 | 18.9 | - / 40.1 |
| | 70 B | - / 63.8 | - / 44.3 | - / 59.3 | 32.3 | - / 60.8 |
| Qwen-Chat | 1.8 B | 42.4 / 43.9 | 50.7 / 50.3 | 27.8 / 19.5 | 14.6 | 27.1 / 25.0 |
| | 7B | 55.8 / 57.0 | 59.7 / 59.3 | 50.3 / 54.1 | 37.2 | 39.6 / 46.7 |
| | 14B | 64.6 / 66.5 | 69.8 / 71.7 | 60.1 / 59.3 | 43.9 | 46.9 / 58.7 |
except ChatGPT (OpenAI, 2022) and Llama 2-Chat-70B (Touvron et al., 2023b) in all datasets, including MMLU (Hendrycks et al., 2020), C-Eval (Huang et al., 2023), GSM8K (Cobbe et al., 2021), HumanEval (Chen et al., 2021), and BBH (Suzgun et al., 2022). In particular, Qwen’s performance in HumanEval, which measures the quality of generated codes, is significantly higher than that of other open-source models.
Moreover, QWEN’s performance is consistently better than that of open-source models of similar size, such as LLaMA2 (Touvron et al., 2023b), ChatGLM2 (ChatGLM2 Team, 2023), InternLM (InternLM) Team, 2023), and Baichuan2 (Yang et al., 2023). This suggests that our alignment approach, which involves fine-tuning the model on a large dataset of human conversations, has been effective in improving the model’s ability to understand and generate human-like language.
Despite this, we have reservations about the ability of traditional benchmark evaluation to accurately measure the performance and potential of chat models trained with alignment techniques in today’s landscape. The results mentioned earlier provide some evidence of our competitive standing, but we believe that it is crucial to develop new evaluation methods specifically tailored to aligned models.
We believe that human evaluation is crucial, which is why we have created a carefully curated dataset for this purpose. Our process involved collecting 300 instructions in Chinese that covered a wide range of topics, including knowledge, language understanding, creative writing, coding, and mathematics. To evaluate the performance of different models, we chose the SFT version of Qwen-Chat-7B and the SFT and RLHF versions of Qwen-Chat-14B, and added two strong baselines, GPT-3.5 and GPT-4 for comparison. For each instruction, we asked three annotators to rank the model responses by the overall score of helpfulness, informativeness, validity, and other relevant factors. Our dataset and evaluation methodology provides a comprehensive and rigorous assessment of the capabilities of different language models in various domains.
Figure 4 illustrates the win rates of the various models. For each model, we report the percentage of wins, ties, and losses against GPT-3.5, with the segments of each bar from bottom to top representing these statistics. The experimental results clearly demonstrate that the RLHF model outperforms the SFT models by significant margins, indicating that RLHF can encourage the model to generate responses that are more preferred by humans. In terms of overall performance, we find that the RLHF model significantly outperforms the SFT models, falling behind GPT-4. This indicates the effectiveness of RLHF for aligning to human preference. To provide a more comprehensive understanding of the models’ performance, we include a case study with examples from different models in Appendix A.2.2. Nonetheless, it remains difficult to accurately capture the gap between our
4
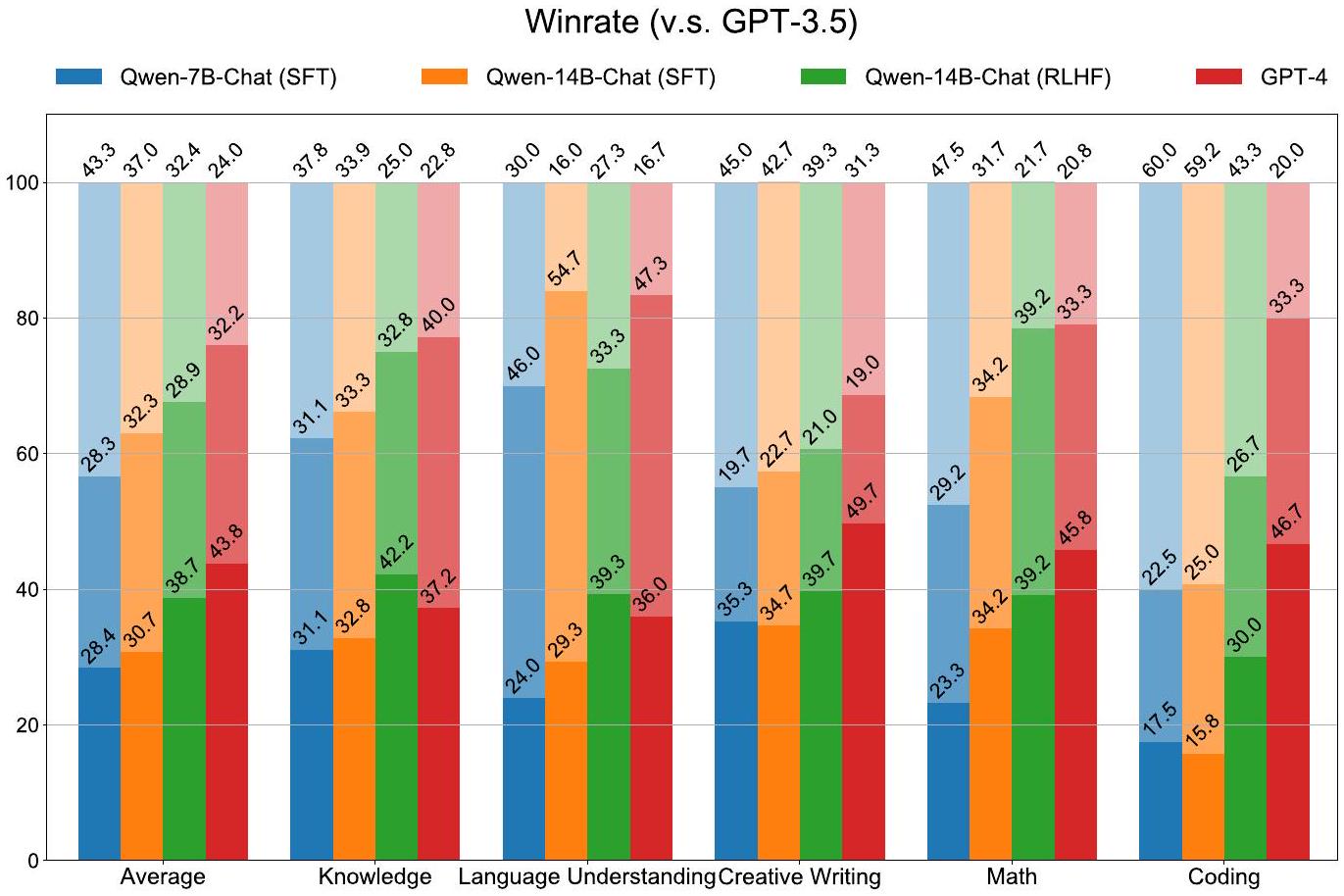
Figure 4: Results of the human evaluation for chat models. We compare Qwen-7B (SFT), Qwen14B (SFT), Qwen-14B (RLHF), as well as GPT-4 against GPT-3.5. Each bar segment represents the percentage of wins, ties, and losses, from bottom to top. On average, the RLHF model outperforms the SFT model. The dataset consists of 300 Chinese instructions.
models and the proprietary models. As such, a more extensive and rigorous assessment is required for the chat models.
3.4 Tool Use, Code Interpreter, and Agent
Table 6: Performance of QWEN on the in-house Chinese benchmark that evaluates its ability to use unseen tools via ReAct prompting.
| Model | Params | Tool Selection (Acc. ) | Tool Input (Rouge-L ↑ ) | False Positive Error (%) ↓ |
| :— | :— | :— | :— | :— |
| GPT-4 | - | 95 | 90 | 15.0 |
| GPT-3.5 | - | 85 | 88 | 75.0 |
| Qwen-Chat | 1.8 B | 92 | 89 | 19.3 |
| | 7B | 98 | 91 | 7.3 |
| | 14B | 98 | 93 | 2.4 |
The QWEN models, which are designed to be versatile, have the remarkable ability to assist with (semi-)automating daily tasks by leveraging their skills in tool-use and planning. As such, they can serve as agents or copilots to help streamline various tasks. We explore Qwen’s proficiency in the following areas:
-
Utilizing unseen tools through ReAct prompting (Yao et al., 2022) (see Table 6).
-
Using a Python code interpreter to enhance math reasoning, data analysis, and more (see Table 7 and Table 8 .
-
Functioning as an agent that accesses Hugging Face’s extensive collection of multimodal models while engaging with humans (see Table 9).
Table 7: The proportion of code generated by QWEN that is executable on the in-house evaluation benchmark for Code Interpreter. This benchmark examines Qwen’s coding proficiency in math problem solving, data visualization, and general purposes. Code LLAMA underperforms on visualization tasks because it hallucinates non-existent columns solely based on CSV file names (see Figure 5).
| Model | Params | Category | | | |
| :— | :— | :— | :— | :— | :— |
| | | Math (%) | Visualization (%) | General (%) | All (%) |
| GPT-4 | - | 91.9 | 85.9 | 82.8 | 86.8 |
| GPT-3.5 | - | 89.2 | 65.0 | 74.1 | 72.9 |
| Llama 2-Chat | 7B | 41.9 | 33.1 | 24.1 | 33.6 |
| | 13B | 50.0 | 40.5 | 48.3 | 44.4 |
| Code LLAMA-Instruct | 7B | 85.1 | 54.0 | 70.7 | 65.1 |
| | 13B | 93.2 | 55.8 | 74.1 | 68.8 |
| InternLM-Chat | 7B v1.1 | 78.4 | 44.2 | 62.1 | 56.3 |
| | 20 B | 70.3 | 44.2 | 65.5 | 54.9 |
| Qwen-Chat | 1.8 B | 33.8 | 30.1 | 8.6 | 26.8 |
| | 7B | 82.4 | 64.4 | 67.2 | 70.2 |
| | 14B | 89.2 | 84.1 | 65.5 | 81.7 |
Table 8: Correctness of the final response on the in-house evaluation benchmark for Code Interpreter. Visualization-Hard tasks involve planning multiple steps, white Visualization-Easy tasks do not. Visualization-All measures both types of tasks. Code LLaMA excels in performing VisualizationEasy tasks but tends to underperform in Visualization-Hard tasks, due to its inclination to hallucinate non-existent columns based on the name of a CSV file (see Figure 5).
| Model | Params | Category | | | |
| :— | :— | :— | :— | :— | :— |
| | | Math (%) | Vis.-Hard (%) | Vis.-Easy (%) | Vis.-All (%) |
| GPT-4 | - | 82.8 | 66.7 | 60.8 | 63.8 |
| GPT-3.5 | - | 47.3 | 33.3 | 55.7 | 44.2 |
| Llama 2-Chat | 7B | 3.9 | 14.3 | 39.2 | 26.4 |
| | 13B | 8.3 | 8.3 | 40.5 | 23.9 |
| Code LLaMA-Instruct | 7B | 14.3 | 26.2 | 60.8 | 42.9 |
| | 13B | 28.2 | 27.4 | 62.0 | 44.2 |
| InternLM-Chat | 7B v1.1 | 28.5 | 4.8 | 40.5 | 22.1 |
| | 20 B | 34.6 | 21.4 | 45.6 | 33.1 |
| Qwen-Chat | 1.8 B | 14.7 | 3.6 | 20.3 | 11.7 |
| | 7B | 41.9 | 40.5 | 54.4 | 47.2 |
| | 14B | 58.4 | 53.6 | 59.5 | 56.4 |
Table 9: Results of Qwen-Chat on the Hugging Face Agent benchmark.
| Task | Model | Params | Metric | | |
| :— | :— | :— | :— | :— | :— |
| | | | Tool Selection ↑ | Tool Used ↑ | Code Correctness ↑ |
| Run Mode | GPT-4 | - | 100 | 100 | 97.4 |
| | GPT-3.5 | - | 95.4 | 96.3 | 87.0 |
| | Starcoder-Base | 15B | 86.1 | 87.0 | 68.9 |
| | Starcoder | 15B | 87.0 | 88.0 | 68.9 |
| | Qwen-Chat | 1.8 B | 85.2 | 84.3 | 61.1 |
| | | 7B | 87.0 | 87.0 | 71.5 |
| | | 14B | 93.5 | 94.4 | 87.0 |
| Chat Mode | GPT-4 | - | 97.9 | 97.9 | 98.5 |
| | GPT-3.5 | - | 97.3 | 96.8 | 89.6 |
| | Starcoder-Base | 15B | 97.9 | 97.9 | 91.1 |
| | Starcoder | 15B | 97.9 | 97.9 | 89.6 |
| | Qwen-Chat | 1.8 B | 93.6 | 93.6 | 73.2 |
| | | 7B | 94.7 | 94.7 | 85.1 |
| | | 14B | 97.9 | 97.9 | 95.5 |
To enhance Qwen’s capabilities as an agent or copilot, we employ the self-instruct (Wang et al. 2023c) strategy for SFT. Specifically, we utilize the in-context learning capability of QWEN for self-instruction. By providing a few examples, we can prompt QWEN to generate more relevant queries and generate outputs that follow a specific format, such as ReAct (Yao et al., 2022). We then apply rules and involve human annotators to filter out any noisy samples. Afterwards, the samples are incorporated into QWEN’s training data, resulting in an updated version of QWEN that is more dependable for self-instruction. We iterate through this process multiple times until we gather an ample number of samples that possess both exceptional quality and a wide range of diversity. As a result, our final collection consists of around 2000 high-quality samples.
During the finetuning process, we mix these high-quality samples with all the other general-purpose SFT samples, rather than introducing an additional training stage. By doing so, we are able to retain essential general-purpose capabilities that are also pertinent for constructing agent applications.
Using Tools via ReAct Prompting We have created and made publicly available a benchmark for evaluating Qwen’s ability to call plugins, tools, functions, or APIs using ReAct Prompting (see Qwen Team, Alibaba Group, 2023b). To ensure fair evaluation, we have excluded any plugins that were included in QWEN’s training set from the evaluation set. The benchmark assesses the model’s accuracy in selecting the correct plugin from a pool of up to five candidates, as well as the plausibility of the parameters passed into the plugin and the frequency of false positives. In this evaluation, a false positive occurs when the model incorrectly invokes a plugin in response to a query, despite not being required to do so.
The results presented in Table 6 demonstrate that QWEN consistently achieves higher accuracy in identifying the relevance of a query to the available tools as the model size increases. However, the table also highlights that beyond a certain point, there is little improvement in performance when it comes to selecting the appropriate tool and providing relevant arguments. This suggests that the current preliminary benchmark may be relatively easy and may require further enhancement in future iterations. It is worth noting that GPT-3.5 stands out as an exception, displaying suboptimal performance on this particular benchmark. This could potentially be attributed to the fact that the benchmark primarily focuses on the Chinese language, which may not align well with GPT-3.5’s capabilities. Additionally, we observe that GPT-3.5 tends to attempt to use at least one tool, even if the query cannot be effectively addressed by the provided tools.
Using Code Interpreter for Math Reasoning and Data Analysis The Python code interpreter is widely regarded as a powerful tool for augmenting the capabilities of an LLM agent. It is
worth investigating whether QWEN can harness the full potential of this interpreter to enhance its performance in diverse domains, such as mathematical reasoning and data analysis. To facilitate this exploration, we have developed and made publicly available a benchmark that is specifically tailored for this purpose (see Qwen Team, Alibaba Group, 2023a).
The benchmark encompasses three primary categories of tasks: math problem-solving, data visualization, and other general-purpose tasks like file post-processing and web crawling. Within the visualization tasks, we differentiate between two levels of difficulty. The easier level can be achieved by simply writing and executing a single code snippet without the need for advanced planning skills. However, the more challenging level requires strategic planning and executing multiple code snippets in a sequential manner. This is because the subsequent code must be written based on the output of the previous code. For example, an agent may need to examine the structure of a CSV file using one code snippet before proceeding to write and execute additional code to create a plot.
Regarding evaluation metrics, we consider both the executability and correctness of the generated code. To elaborate on the correctness metrics, for math problems, we measure accuracy by verifying if the ground truth numerical answer is present in both the code execution result and the final response. When it comes to data visualization, we assess accuracy by utilizing Qwen-VL (Bai et al., 2023), a powerful multimodal language model. QWEN-VL is capable of answering text questions paired with images, and we rely on it to confirm whether the image generated by the code fulfills the user’s request.
The results regarding executability and correctness are presented in Table 7 and Table 8, respectively. It is evident that Code LLaMA generally outperforms Llama 2, its generalist counterpart, which is not surprising since this benchmark specifically requires coding skills. However, it is worth noting that specialist models that are optimized for code synthesis do not necessarily outperform generalist models. This is due to the fact that this benchmark encompasses various skills beyond coding, such as abstracting math problems into equations, understanding language-specified constraints, and responding in the specified format such as ReAct. Notably, Qwen-7B-Chat and Qwen-14B-Chat surpass all other open-source alternatives of similar scale significantly, despite being generalist models.
Serving as a Hugging Face Agent Hugging Face provides a framework called the Hugging Face Agent or Transformers Agent (Hugging Face, 2023), which empowers LLM agents with a curated set of multimodal tools, including speech recognition and image synthesis. This framework allows an LLM agent to interact with humans, interpret natural language commands, and employ the provided tools as needed.
To evaluate Qwen’s effectiveness as a Hugging Face agent, we utilized the evaluation benchmarks offered by Hugging Face. The results are presented in Table 9. The evaluation results reveal that QWEN performs quite well in comparison to other open-source alternatives, only slightly behind the proprietary GPT-4, demonstrating Qwen’s competitive capabilities.
4 Code-Qwen: Specialized Model for Coding
Training on domain-specific data has been shown to be highly effective, particularly in the case of code pretraining and finetuning. A language model that has been reinforced with training on code data can serve as a valuable tool for coding, debugging, and interpretation, among other tasks. In this work, we have developed a series of generalist models using pretraining and alignment techniques. Building on this foundation, we have created domain-specific models for coding by leveraging the base language models of QWEN, including continued pretrained model, Code-Qwen and supervised finetuned model, Code-Qwen-Chat. Both models have 14 billion and 7 billion parameters versions.
4.1 Code Pretraining
We believe that relying solely on code data for pretraining can result in a significant loss of the ability to function as a versatile assistant. Unlike previous approaches that focused solely on pretraining on code data (Li et al., 2022; 2023d), we take a different approach (Rozière et al., 2023) by starting with our base models QWEN trained on a combination of text and code data, and then continuing to
pretrain on the code data. We continue to pretrain the models on a total of around 90 billion tokens. During the pre-training phase, we initialize the model using the base language models Qwen. Many applications that rely on specialized models for coding may encounter lengthy contextual scenarios, such as tool usage and code interpretation, as mentioned in Section 3.4. To address this issue, we train our models with context lengths of up to 8192. Similar to base model training in Section 2.4, we employ Flash Attention (Dao et al., 2022) in the attention modules, and adopt the standard optimizer AdamW (Kingma & Ba 2014; Loshchilov & Hutter, 2017), setting , and . We set the learning rate as for CODE-QWEN-14B and for Code-Qwen-7B, with warm up iterations and no learning rate decays.
4.2 Code Supervised Fine-Tuning
After conducting a series of empirical experiments, we have determined that the multi-stage SFT strategy yields the best performance compared to other methods. In the supervised fine-tuning stage, the model Code-Qwen-Chat initialized by the code foundation model Code-Qwen are optimized by the AdamW (Kingma & Ba, 2014, Loshchilov & Hutter, 2017) optimizer ( , ) with a learning rate of and for the 14 B and 7 B model respectively. The learning rate increases to the peaking value with the cosine learning rate schedule ( warm-up steps) and then remains constant.
4.3 Evaluation
Our Code-Qwen models have been compared with both proprietary and open-source language models, as shown in Tables 10 and 11. These tables present the results of our evaluation on the test sets of Humaneval (Chen et al., 2021), MBPP (Austin et al., 2021), and the multi-lingual code generation benchmark HumanEvalPack (Muennighoff et al., 2023). The comparison is based on the pass@1 performance of the models on these benchmark datasets. The results of this comparison are clearly demonstrated in Tables 10 and 11.
Our analysis reveals that specialized models, specifically Code-Qwen and Code-Qwen-Chat, significantly outperform previous baselines with similar parameter counts, such as OctoGeeX (Muennighoff et al., 2023), InstructCodeT5+ (Wang et al., 2023d), and CodeGeeX2 (Zheng et al., 2023). In fact, these models even rival the performance of larger models like Starcoder (Li et al., 2023d).
When compared to some of the extremely large-scale closed-source models, Code-Qwen and Code-QWEN-CHAT demonstrate clear advantages in terms of pass@1. However, it is important to note that these models fall behind the state-of-the-art methods, such as GPT-4, in general. Nonetheless, with the continued scaling of both model size and data size, we believe that this gap can be narrowed in the near future.
It is crucial to emphasize that the evaluations mentioned previously are insufficient for grasping the full extent of the strengths and weaknesses of the models. In our opinion, it is necessary to develop more rigorous tests to enable us to accurately assess our relative performance in comparison to GPT-4.
5 Math-Qwen: Specialized Model for Mathematics Reasoning
We have created a mathematics-specialized model series called Math-Qwen-Chat, which is built on top of the QWEN pretrained language models. Specifically, we have developed assistant models that are specifically designed to excel in arithmetic and mathematics and are aligned with human behavior. We are releasing two versions of this model series, Math-Qwen-14B-Chat and Math-Qwen-7B-Chat, which have 14 billion and 7 billion parameters, respectively.
5.1 Training
We carry out math SFT on our augmented math instructional dataset for mathematics reasoning, and therefore we obtain the chat model, Math-Qwen-Chat, directly. Owing to shorter average lengths of the math SFT data, we use a sequence length of 1024 for faster training. Most user inputs in the math SFT dataset are examination questions, and it is easy for the model to predict the input
Table 10: Results of pass@1 (%) on HumanEval and MBPP. Most scores are retrieved from the papers of StarCoder (Li et al., 2023d), CodeT5+ (Wang et al., 2023d), WizardCoder (Luo et al., 2023b) and Code LLAMA (Rozière et al., 2023).
| Model | Params | HumanEval | MBPP |
| :— | :— | :— | :— |
| Proprietary models | | | |
| PaLM | 540B | 26.2 | 36.8 |
| PaLM-Coder | 540B | 36.0 | 47.0 |
| PaLM 2-S | - | 37.6 | 50.0 |
| Code-Cushman-001 | - | 33.5 | 45.9 |
| Code-Davinci-002 | - | 47.0 | 58.1 |
| GPT-3.5 | - | 73.2 | - |
| GPT-4 | - | 86.6 | - |
| Open-source models | | | |
| Llama 2 | 7B | 12.2 | 20.8 |
| | 13 B | 20.1 | 27.6 |
| | 34B | 22.6 | 33.8 |
| | 70B | 30.5 | 45.4 |
| CodeGen-Multi | 16B | 18.3 | 20.9 |
| CodeGen-Mono | 16B | 29.3 | 35.3 |
| CodeGeeX2 | 6B | 35.9 | - |
| StarCoder-Prompted | 15B | 40.8 | 49.5 |
| CodeT5+ | 16B | 30.9 | - |
| InstructCodeT5+ | 16B | 35.0 | - |
| Code LLaMA | 7B | 33.5 | 41.4 |
| | 13 B | 36.0 | 47.0 |
| | 34B | 48.8 | 55.0 |
| Code Llama-Instruct | 7B | 34.8 | 44.4 |
| | 13 B | 42.7 | 49.4 |
| | 34B | 41.5 | 57.0 |
| Code Llama-Python | 7B | 38.4 | 47.6 |
| | 13B | 43.3 | 49.0 |
| | 34B | 53.7 | 56.2 |
| Unnatural Code Llama | 34B | 62.2 | 61.2 |
| WizardCoder-Python | 13B | 64.0 | 55.6 |
| | 34B | 73.2 | 61.2 |
| Qwen-Chat | 7B | 37.2 | 35.8 |
| | 14B | 43.9 | 46.4 |
| Code-Qwen | 7B | 40.2 | 41.8 |
| | 14B | 45.1 | 51.4 |
| Code-Qwen-Chat | 7B | 43.3 | 44.2 |
| | 14B | 66.4 | 52.4 |
Table 11: Zero-shot pass@1 (%) performance on the HumanEvalPACK (synthesize) benchmark. The baseline results are partly from ОстоРack (Muennighoff et al., 2023).
| Model | Params | Programming Language | | | | | | |
| :— | :— | :— | :— | :— | :— | :— | :— | :— |
| | | Python | JavaScript | Java | Go | C++ | Rust | Avg. |
| Proprietary models | | | | | | | | |
| GPT-4 | - | 86.6 | 82.9 | 81.7 | 72.6 | 78.7 | 67.1 | 78.3 |
| Open-source models | | | | | | | | |
| InstructCodeT5+ | 16B | 37.0 | 18.9 | 17.4 | 9.5 | 19.8 | 0.3 | 17.1 |
| StarChat- | 15B | 33.5 | 31.4 | 26.7 | 25.5 | 26.6 | 14.0 | 26.3 |
| StarCoder | 15B | 33.6 | 30.8 | 30.2 | 17.6 | 31.6 | 21.8 | 27.6 |
| CodeGeeX2 | 6B | 35.9 | 32.2 | 30.8 | 22.5 | 29.3 | 18.1 | 28.1 |
| OctoGeeX | 6B | 44.7 | 33.8 | 36.9 | 21.9 | 32.3 | 15.7 | 30.9 |
| OctoCoder | 15B | 46.2 | 39.2 | 38.2 | 30.4 | 35.6 | 23.4 | 35.5 |
| WizardCoder | 15B | 59.8 | 49.5 | 36.1 | 36.4 | 40.9 | 20.2 | 40.5 |
| Qwen-Chat | 7B | 37.2 | 23.2 | 32.9 | 20.7 | 22.0 | 9.1 | 24.2 |
| | 14B | 43.9 | 38.4 | 42.7 | 34.1 | 24.4 | 18.9 | 33.7 |
| Code-Qwen | 7B | 40.2 | 40.4 | 40.2 | 26.2 | 20.7 | 15.8 | 30.6 |
| | 14B | 45.1 | 51.8 | 57.3 | 39.6 | 18.2 | 20.7 | 38.8 |
| Code-Qwen-Chat | 7B | 43.3 | 41.5 | 49.4 | 29.3 | 32.9 | 20.1 | 36.1 |
| | 14B | 66.4 | 58.5 | 56.1 | 47.6 | 54.2 | 28.7 | 51.9 |
Table 12: Results of models on mathematical reasoning. We report the accuracy of QWEN for all benchmarks using greedy decoding. For MATH, we are reporting Qwen’s performances on the test set from Lightman et al. (2023).
| Model | Params | GSM8K | MATH | Math401 | Math23K |
| :— | :— | :— | :— | :— | :— |
| Proprietary models | | | | | |
| GPT-4 | - | 92.0 | 42.5 | 83.5 | 74.0 |
| GPT-3.5 | - | 80.8 | 34.1 | 75.1 | 60.0 |
| Minerva | 8B | 16.2 | 14.1 | - | - |
| | 62B | 52.4 | 27.6 | - | - |
| | 540B | 58.8 | 33.6 | - | - |
| Open-source models | | | | | |
| LLaMA-1 RFT | 7B | 46.5 | 5.2 | - | - |
| | 13 B | 52.1 | 5.1 | - | - |
| WizardMath | 7B | 54.9 | 10.7 | - | - |
| | 13B | 63.9 | 14.0 | - | - |
| | 70 B | 81.6 | 22.7 | - | - |
| GAIRMath-Abel | 7B | 59.7 | 13.0 | - | - |
| | 13 B | 66.4 | 17.3 | - | - |
| | 70 B | 83.6 | 28.3 | - | - |
| Qwen-Chat | 7B | 50.3 | 6.8 | 57.4 | 51.2 |
| | 14B | 60.1 | 18.4 | 70.1 | 67.0 |
| Math-Qwen-Chat | 7B | 62.5 | 17.2 | 80.8 | 75.4 |
| | 14B | 69.8 | 24.2 | 85.0 | 78.4 |
format and it is meaningless for the model to predict the input condition and numbers which could be random. Thus, we mask the inputs of the system and user to avoid loss computation on them and find masking them accelerates the convergence during our preliminary experiments. For optimization, we use the AdamW optimizer with the same hyperparameters of SFT except that we use a peak learning rate of and a training step of 50000 .
5.2 Evaluation
We evaluate models on the test sets of GSM8K (Grade school math) (Cobbe et al., 2021), MATH (Challenging competition math problems) (Hendrycks et al., 2021), Math401 (Arithmetic ability) (Yuan et al., 2023b), and Math23K (Chinese grade school math) (Wang et al., 2017). We compare Math-Qwen-Chat with proprietary models ChatGPT and Minerva (Lewkowycz et al., 2022) and open-sourced math-specialized model RFT (Yuan et al., 2023a), WizardMath (Luo et al., 2023a), and GAIRMath-Abel (Chern et al., 2023a) in Table 12. Math-Qwen-Chat models show better math reasoning and arithmetic abilities compared to open-sourced models and QWEN-CHAT models of similar sizes. Compared to proprietary models, Math-Qwen-7B-Chat outperforms Minerva-8B in MATH. MATH-Qwen-14B-Chat is chasing Minerva-62B and GPT-3.5 in GSM8K and MATH and delivers better performance on arithmetic ability and Chinese math problems.
6 Related Work
6.1 Large Language Models
The excitement of LLM began with the introduction of the Transformer architecture (Vaswani et al. 2017), which was then applied to pretraining large-scale data by researchers such as Radford et al. (2018); Devlin et al. (2018); Liu et al. (2019). These efforts led to significant success in transfer learning, with model sizes growing from 100 million to over 10 billion parameters (Raffel et al. 2020; Shoeybi et al., 2019).
In 2020, the release of GPT-3, a massive language model that is 10 times larger than T5, demonstrated the incredible potential of few-shot and zero-shot learning through prompt engineering and in-context learning, and later chain-of-thought prompting (Wei et al., 2022c). This success has led to a number of studies exploring the possibilities of further scaling these models (Scao et al., 2022; Zhang et al., 2022; Du et al., 2021; Zeng et al., 2022; Lepikhin et al., 2020; Fedus et al., 2022; Du et al., 2022; Black et al., 2022; Rae et al., 2021; Hoffmann et al., 2022; Chowdhery et al., 2022; Thoppilan et al. 2022). As a result, the community has come to view these large language models as essential foundations for downstream models (Bommasani et al., 2021).
The birth of ChatGPT (OpenAI, 2022) and the subsequent launch of GPT-4 (OpenAI 2023) marked two historic moments in the field of artificial intelligence, demonstrating that large language models (LLMs) can serve as effective AI assistants capable of communicating with humans. These events have sparked interests among researchers and developers in building language models that are aligned with human values and potentially even capable of achieving artificial general intelligence (AGI) (Anil et al., 2023, Anthropic, 2023a b).
One notable development in this area is the emergence of open-source LLMs, specifically LLaMA (Touvron et al., 2023a) and Llama 2 (Touvron et al., 2023b), which have been recognized as the most powerful open-source language models ever created. This has led to a surge of activity in the open-source community (Wolf et al., 2019), with a series of large language models being developed collaboratively to build upon this progress (Mosaic ML, 2023, Almazrouei et al., 2023; ChatGLM2 Team, 2023, Yang et al., 2023; InternLM Team, 2023).
6.2 Alignment
The community was impressed by the surprising effectiveness of alignment on LLMs. Previously, LLMs without alignment often struggle with issues such as repetitive generation, hallucination, and deviation from human preferences. Since 2021, researchers have been diligently working on developing methods to enhance the performance of LLMs in downstream tasks (Wei et al., 2022a; Sanh et al., 2021; Longpre et al., 2023; Chung et al., 2022; Muennighoff et al., 2022). Furthermore,
researchers have been actively exploring ways to align LLMs with human instructions (Ouyang et al., 2022; Askell et al., 2021; Bai et al., 2022b c). One major challenge in alignment research is the difficulty of collecting data. While OpenAI has utilized its platform to gather human prompts or instructions, it is not feasible for others to collect such data.
However, there has been some progress in this area, such as the self-instruct approach proposed in Wang et al. (2023c). This innovative work offers a potential solution to the data collection problem in alignment research. As a result, there has been a surge in open-source chat data, including Alpaca (Taori et al., 2023), MOSS (Sun et al., 2023a), Dolly (Conover et al., 2023), Evol-Instruct (Xu et al., 2023b), and others (Sun et al., 2023b; Xu et al., 2023a c, Chen et al., 2023c, Ding et al., 2023; Ji et al., 2023, Yang, 2023). Similarly, there has been an increase in open-source chat models, such as Alpaca (Taori et al., 2023), Vicuna (Chiang et al., 2023), Guanaco (Dettmers et al., 2023), MOSS (Sun et al., 2023a), WizardLM (Xu et al., 2023b), and others (Xu et al., 2023c; Chen et al., 2023c; Ding et al., 2023; Wang et al., 2023b).
To train an effective chat model, available solutions are mostly based on SFT and RLHF (Ouyang et al., 2022). While SFT is similar to pretraining, it focuses on instruction following using the aforementioned data. However, for many developers, the limited memory capacity is a major obstacle to further research in SFT. As a result, parameter-efficient tuning methods, such as LoRA (Hu et al., 2021) and Q-LoRA (Dettmers et al., 2023), have gained popularity in the community. LoRA tunes only low-rank adapters, while Q-LoRA builds on LoRA and utilizes 4-bit quantized LLMs and paged attention (Dettmers et al., 2022; Frantar et al., 2022; Kwon et al., 2023). In terms of RLHF, recent methods such as PPO (Schulman et al., 2017, Touvron et al., 2023b) have been adopted, but there are also alternative techniques aimed at addressing the complexity of optimization, such as RRHF (Yuan et al., 2023c), DPO (Rafailov et al., 2023), and PRO (Song et al., 2023). Despite the ongoing debate about the effectiveness of RLHF, more evidence is needed to understand how it enhances the intelligence of LLMs and what potential drawbacks it may have.
6.3 Tool Use and Agents
LLM’s planning function allows for the invocation of tools, such as APIs or agent capabilities, through in-context learning, as demonstrated by Schick et al. (2023). Yao et al., (2022) introduced ReAct, a generation format that enables the model to generate thoughts on which tool to use, accept input from API observations, and generate a response. GPT-3.5 and GPT-4, when prompted with few shots, have shown consistent and impressive performance. In addition to tool usage, LLMs can utilize external memory sources like knowledge bases (Hu et al., 2023; Zhong et al., 2023b) or search engines (Nakano et al., 2021, Liu et al., 2023b) to generate more accurate and informative answers. This has led to the popularity of frameworks like LangChain (LangChain, Inc., 2023). The research on LLMs for tool use has also sparked interest in building agents with LLM capabilities, such as agents that can call different AI models (Shen et al., 2023; Li et al., 2023a), embodied lifelong learning or multimodal agents (Wang et al., 2023a; Driess et al., 2023), and multiple agents interacting with each other and even building a micro-society (Chen et al., 2023b; Li et al., 2023b; Xu et al., 2023d; Hong et al., 2023).
6.4 LLM For Coding
Previous research has demonstrated that LLMs possess remarkable capabilities in code understanding and generation, particularly those with massive numbers of parameters (Chowdhery et al., 2022; Anil et al., 2023, Rae et al., 2021, Hoffmann et al., 2022). Moreover, several LLMs have been pretrained, continued pre-trained, or fine-tuned on coding-related data, which has resulted in significantly improved performance compared to general-purpose LLMs. These models include Codex Chen et al. (2021), AlphaCode (Li et al., 2022), SantaCoder (Allal et al., 2023), Starcoder-Base (Li et al., 2023d), InCoder (Fried et al., 2022), CodeT5 (Wang et al., 2021), CodeGeeX (Zheng et al., 2023), and Code LLaMA (Rozière et al., 2023). In addition to these models, recent studies have focused on developing specialized alignment techniques for coding, such as Code Llama-Instruct (Rozière et al., 2023) and StarCoder (Li et al., 2023d). These models can assist developers in various code-related tasks, including code generation (Chen et al., 2021; Austin et al., 2021), code completion (Zhang et al., 2023a), code translation (Szafraniec et al., 2023), bug fixing (Muennighoff et al., 2023), code refinement (Liu et al., 2023c), and code question answering (Liu & Wan, 2021). In a word, LLMs
have the potential to revolutionize the field of coding by providing developers with powerful tools for code comprehension, generation, and related tasks.
6.5 LLM for Mathematics
LLMs with a certain model scale have been found to possess the ability to perform mathematical reasoning (Wei et al., 2022b; Suzgun et al., 2022). In order to encourage LLMs to achieve better performance on math-related tasks, researchers have employed techniques such as chain-of-thought prompting (Wei et al., 2022c) and scratchpad (Nye et al., 2021), which have shown promising results. Additionally, self-consistency (Wang et al., 2022) and least-to-most prompting (Zhou et al., 2022) have further improved the performance of these models on these tasks. However, prompt engineering is a time-consuming process that requires a lot of trial and error, and it is still difficult for LLMs to consistently perform well or achieve satisfactory results in solving mathematical problems. Moreover, simply scaling the data and model size is not an efficient way to improve a model’s mathematical reasoning abilities. Instead, pretraining on math-related corpora has been shown to consistently enhance these capabilities (Hendrycks et al., 2021; Lewkowycz et al., 2022; Taylor et al., 2022; Lightman et al., 2023). Additionally, fine-tuning on math-related instruction-following datasets (Si et al., 2023; Yuan et al., 2023a; Luo et al., 2023a; Yue et al., 2023; Chern et al., 2023a; Yu et al., 2023), has also been effective and more cost-effective than math-specific pretraining. Despite their limitations in terms of accuracy, LLMs still have significant potential to assist users with practical mathematical problems. There is ample scope for further development in this area.
7 Conclusion
In this report, we present the QWEN series of large language models, which showcase the latest advancements in natural language processing. With , and 1.8 B parameters, these models have been pre-trained on massive amounts of data, including trillions of tokens, and fine-tuned using cutting-edge techniques such as SFT and RLHF. Additionally, the Qwen series includes specialized models for coding and mathematics, such as Code-Qwen, Code-Qwen-Chat, and Math-QwenChat, which have been trained on domain-specific data to excel in their respective fields. Our results demonstrate that the QWEN series is competitive with existing open-source models and even matches the performance of some proprietary models on comprehensive benchmarks and human evaluation.
We believe that the open access of QWEN will foster collaboration and innovation within the community, enabling researchers and developers to build upon our work and push the boundaries of what is possible with language models. By providing these models to the public, we hope to inspire new research and applications that will further advance the field and contribute to our understanding of the variables and techniques introduced in realistic settings. In a nutshell, the Qwen series represents a major milestone in our development of large language models, and we are excited to see how it will be used to drive progress and innovation in the years to come.
-
Authors are ordered alphabetically by the last name. Correspondence to: ericzhou.zc@alibaba-inc.com. Qwen is a moniker of Qianwen, which means “thousands of prompts” in Chinese. The pronunciation of “Qwen” can vary depending on the context and the individual speaking it. Here is one possible way to pronounce it: /kwɛn/.↩︎
-
The dataset contains academic papers from https://arxiv.org↩︎
-
To obtain the results from the models, we use the OpenAI APIs of GPT-3.5-turbo-0613 and GPT-4-0613.↩︎