论文信息
-
标题: Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
-
作者: Zhifei Xie, Changqiao Wu
-
arXiv: 2408.16725v3
-
代码与模型: GitHub
Motivation
现状+问题:
-
GPT-4o 展示了实时对话能力,达到近乎人类的自然流畅度,树立了新的里程碑
-
但学术界模型仍依赖额外的 TTS 系统做语音合成,带来不可接受的延迟
-
现有模型无法直接在音频模态上进行推理并**流式生成(streaming)**输出
目标:
-
构建一个 audio-based end-to-end conversational model,支持实时语音交互
-
在推理时能够 “hear, talk while thinking” — 边思考边说话
Contribution

-
首个完全端到端、开源的实时语音交互模型(Mini-Omni)
-
提出 text-instructed speech generation 方法 — 用文本指导语音生成
-
提出 batch-parallel 推理策略 — 进一步提升推理性能
-
提出 “Any Model Can Talk” 训练方法 — 以最小的语言能力损失赋予任意模型语音交互能力
-
发布 VoiceAssistant-400K 数据集 — 用于 fine-tune 语音输出优化模型
Method
3.1 音频语言建模(Audio Language Modeling)
核心思路:把语音信号离散化后,和文本共享同一个词表,统一建模。
-
连续语音信号经过 SNAC tokenizer 转为离散语音 token(dst),来自词表
-
将文本词表和语音词表合并:
-
合并后的序列 可以是纯文本、纯语音、或二者混合,统一用自回归方式建模:
-
训练时,文本和音频 token 同时生成,loss 是所有 head 的负对数似然之和
3.2 解码策略(Decoding Strategies)
Audio Generation with text instruction
关键问题:LLM 的推理能力都在文本模态上,怎么把这个能力迁移到音频输出?
做法: 文本和音频 token 并行生成,但文本走在前面。
架构:模型有 8 个并行输出头:1 个 text head + 7 个 audio head(对应 SNAC 的 7 层 codebook)
数据流:
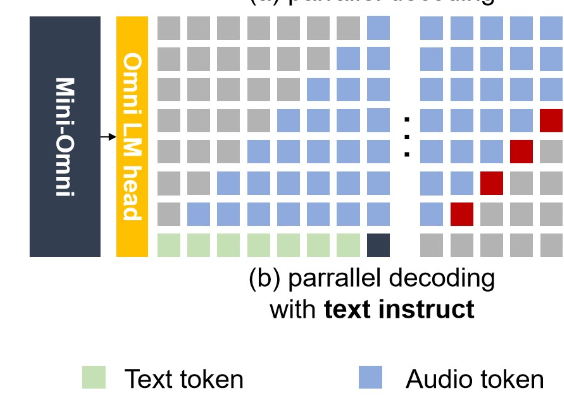
- 8 个 head 共享同一个 Transformer backbone 的隐状态 ,各自做线性投影 → softmax → 采样
- 同一时间步内,不同模态的 embedding 求和后作为下一步的输入
- 跨时间步之间做标准的 causal self-attention
Important
一句话:空间上求和融合,时间上 attention 建模。 整个架构就是一个标准 Transformer + 多输出头,没有额外的复杂结构。
Text-delay Parallel Decoding(延迟模式)
受 MusicGen 启发,各层 audio head 之间保持一步延迟:
-
Text head 先输出 → Audio L1 延迟 1 步 → Audio L2 延迟 2 步 → … → Audio L7 延迟 7 步
ps:delay 不是额外模块,只是 target 序列的排列方式,训练时数据按这个错位排好即可
Batch Parallel Decoding(批次并行解码)
解决的问题:纯并行生成时,音频回复质量不如文本(推理能力没完全迁移过来)。
做法: 推理时 batch size = 2:
-
样本 1:同时生成文本 + 音频(但文本质量可能较弱)
-
样本 2:只生成文本(专注推理,质量高)
-
关键操作:丢弃样本 1 的文本输出,用样本 2 的高质量文本替换进去,音频基于这个好文本来合成
Important
我的理解: Batch = 音频的嘴 + 文本的脑。用极小的额外开销(多跑一路纯文本),就把文本推理能力几乎完整地迁移到了音频模态。从 case study 看效果非常明显——Omni-BATCH 的回复丰富度和纯文本模式几乎一致。
3.3 Any Model Can Talk(让任何模型都能说话)
训练目标:赋予 LLM 语音交互能力的同时,最大限度保留原始文本能力。
输入输出设计
-
输入端:Whisper 编码器提取连续特征 → Adapter 映射到模型维度(不用 SNAC 离散 token)
-
输出端:8 个 LM head 并行输出 1 个 text token + 7 层 SNAC 离散 audio token
-
输入端和输出端用的是两套完全不同的音频表示,各取所长
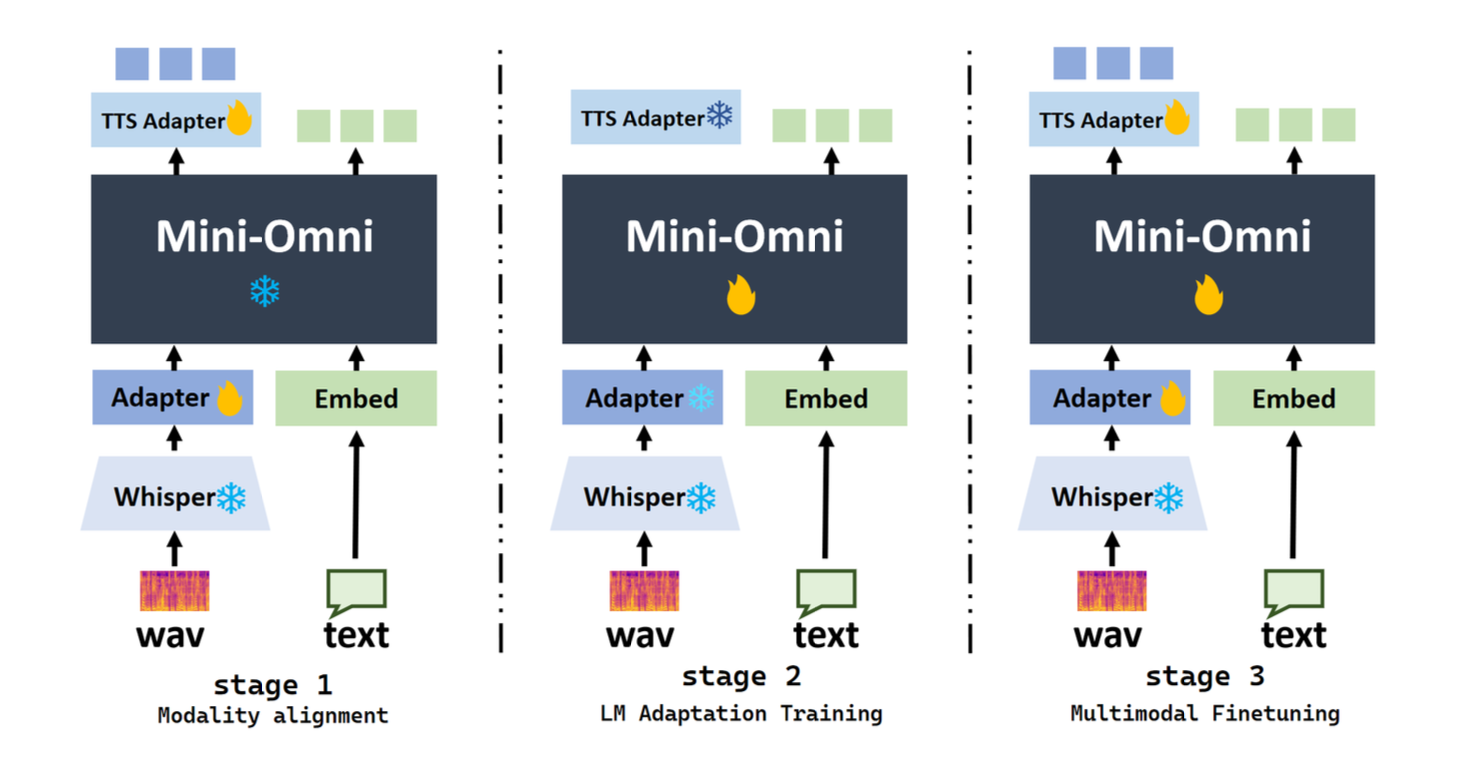
三阶段训练
-
模态对齐(Modality Alignment)
-
冻结核心模型,只训练两个 Adapter(输入端 + 输出端 TTS Adapter)
-
数据:语音识别 + 语音合成
-
目的:让模型”听得懂”语音、“说得出”语音
-
-
适应训练(Adaption Training)
-
冻结 Adapter,训练核心模型
-
数据:语音识别、口语问答、文本回复
-
目的:让模型”听懂后能给出好的文本回复”(音频输出此时仅从文本合成,不需要单独优化)
-
-
多模态微调(Multi-modal Finetuning)
-
全部解冻,综合数据联合微调
-
目的:端到端打磨,文本 + 音频能力协同提升
-
Important
设计哲学: 先对齐模态(adapter 当翻译官),再训练理解(核心模型学新技能),最后联合打磨。渐进式训练保证了原始 LLM 能力不被破坏。
数据集(Datasets)
模型训练总共用了约 8000 小时语音识别数据 + 200 万条文本 QA + 150 万条合成语音 QA + 自建的 VoiceAssistant-400K。
模态记号说明:T = 文本,A = 音频,下标 1 = 输入,2 = 输出。
Stage 1:模态对齐
仅用 ASR 数据训练 Adapter:
-
Libritts(586h)、VCTK(44h)、Multilingual LibriSpeech(8000h)
-
模态:A1|T1(语音输入 → 文本输出)
Stage 2:适应训练
加入文本 QA 和音频 QA:
-
ASR 数据(同 Stage 1)
-
Open-Orca(2000K 条文本 QA,T1|T2)—— 用于保持文本推理能力
Stage 3:多模态微调
加入音频模态的多模态交互数据:
-
Moss-002-sft-data(1500K,A1|T1|A2|T2)—— 用 zero-shot TTS 合成的语音 QA 对
-
ASR + Open-Orca 继续使用
Final:退火 + 微调
使用自建的 VoiceAssistant-400K 数据集:
-
构建方式:用 GPT-4o 生成文本对话,再用 TTS 合成语音,过滤掉不适合的代码/符号输出
-
数据源:Alpaca-GPT4(55K)、Identity finetune(2K)、QAassistant(27K)、RLHF(367K)、Trivia-singlechoice(17K)、Trivia-Multichoice(20K)、OpenAssistant(2K)
-
模态:A1|T1|A2|T2(语音问 → 文本+语音答)
Important
为什么要自建 VoiceAssistant-400K? 现有数据集要么是纯 ASR(只有转录),要么是纯 TTS(单向合成),缺少“语音问 → 语音答”的完整对话数据。所以作者用 GPT-4o + TTS 合成了这批数据,专门用于最后阶段的语音对话微调。
Experiment