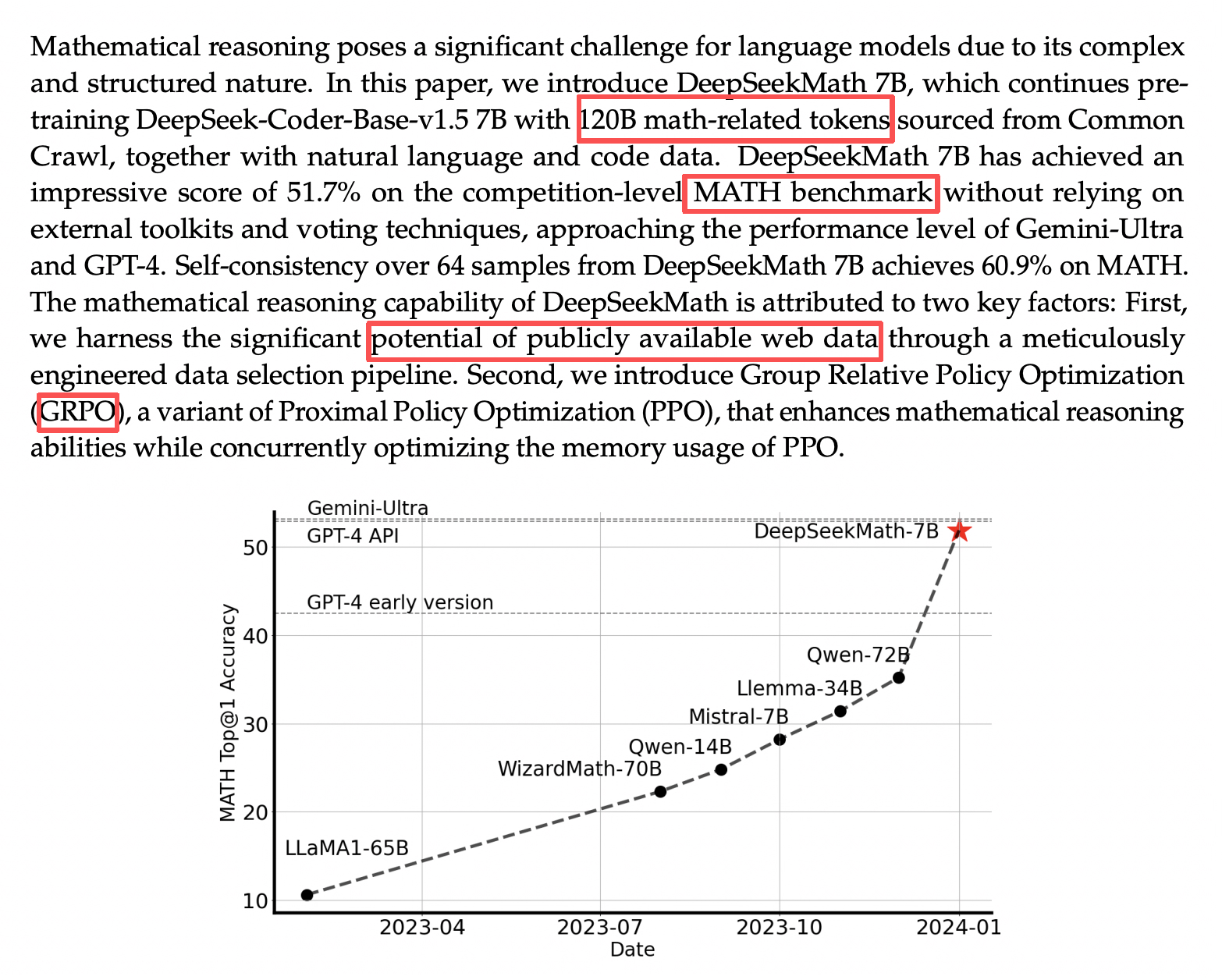
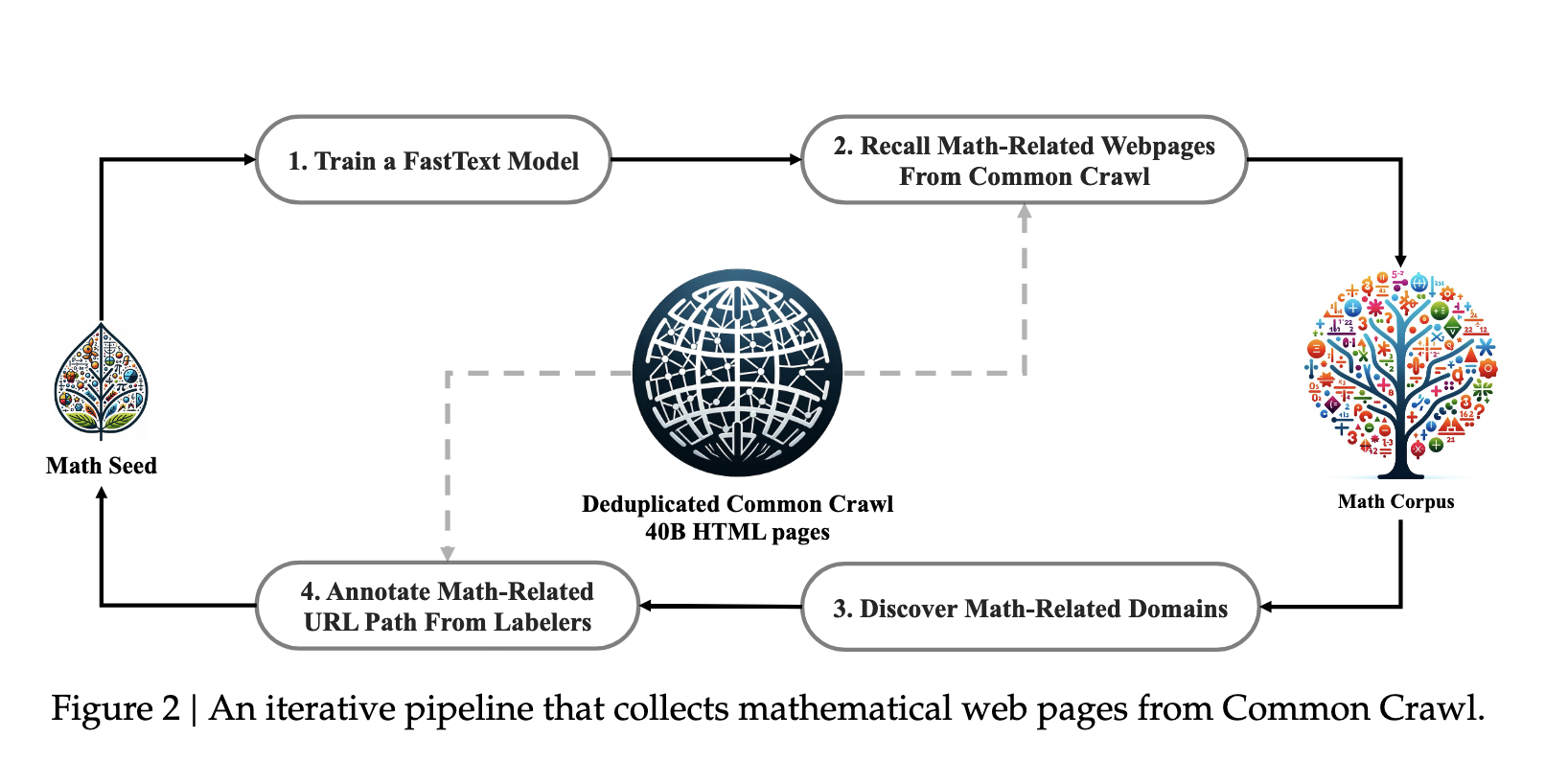
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
核心流程
flowchart LR A["DeepSeek-Coder-Base"] -->|"math continued pretraining"| B["DeepSeekMath-Base"] B -->|"SFT"| C["DeepSeekMath-Instruct"] C -->|"GRPO reinforcement learning"| D["DeepSeekMath-RL"]
Math Continued Pretraining
Math Seed 初始化为 OpenWebMath 的 50 万条正样本;Common Crawl 里随机抽 50 万普通网页作为负样本。
SFT
数据
总量是 776K 条数学 instruction tuning examples
数据格式:
| 格式 | 作用 |
|---|---|
| CoT(chain-of-thought) | 让模型用自然语言一步步推理 |
| PoT(program-of-thought) | 让模型把部分推理写成程序 |
| Tool-integrated reasoning | 让模型结合自然语言推理和工具/代码求解 |
训练细节
- 基座:
DeepSeekMath-Base 7B - 训练样本会随机拼接,直到接近 4K tokens 的最大上下文长度。
- 训练 500 steps。
- batch size = 256。
- learning rate =
5e-5,constant schedule。
GRPO。KL - 0.8 - 1.2
Missing image: Pasted image 20260430170048.png
From PPO to GRPO
PPO 是 actor-critic 结构:一边训练 policy model,一边还要训练一个 value model 来估计 advantage。
| 符号 | 含义 |
|---|---|
| question | |
| policy 采样出来的完整回答 | |
| 回答里的第 个 token | |
| 当前正在训练的 policy model | |
| 采样时用的 old policy | |
| 第 个 token 的 advantage | |
| PPO 的 clipping 范围 |
PPO 里的 通常用 critic / value model 算出来。最朴素地看:
也就是:实际拿到的未来回报 减去 critic 预估的未来回报。 ,说明这个 token 后面的结果比 critic 预期更好;,说明比预期更差。
实际 PPO 常用 GAE(Generalized Advantage Estimation)来降低方差:
这里的 来自 critic (value model)。它的架构通常不是另一个会生成文本的 decoder head,而是:
flowchart TD A["q + o_{≤t} tokens"] --> B["Transformer backbone"] B --> C["hidden state at each token"] C --> D["value head: hidden_dim → 1"] D --> E["V_ψ(q, o_{≤t})"]
也就是说,policy head 输出的是“下一个 token 的概率分布”,critic/value head 输出的是“当前位置往后预期能拿到多少 reward”的一个标量。
这里 是当前 token 位置的 TD error, 控制未来 reward 的折扣, 控制 advantage 估计在“低方差”和“低偏差”之间的折中。
PPO 的 通常依赖 value model / critic 来估计。
对 LLM RL 来说,这会带来两个麻烦:
- value model 通常和 policy model 差不多大,显存和计算开销很重。
- 数学题的 reward 往往只在最后答案处给出,但 PPO 需要每个 token 的 advantage,这会让 value function 的训练变得别扭。
GRPO 的核心动机就是:不要额外训练 value model,而是对同一个问题采样一组回答,用组内 reward 的相对高低来估计 baseline 和 advantage。
GRPO
GRPO 对每个问题 不只采样一个回答,而是从 old policy 里采样一组回答:
然后 reward model 分别给这些回答打分,再通过组内相对比较得到每个回答、每个 token 的 advantage 。GRPO 的目标函数可以写成:
其中:
这里的 是 importance sampling ratio, 它衡量当前 policy 相对 old policy,把这个 token 概率放大或缩小了多少。
在 outcome supervision GRPO 里,每个回答 只有一个最终 reward score 。GRPO 用同一组回答的 reward 做归一化,得到相对 advantage:
其中 。注意这里 和 无关,所以同一个回答 里的所有 token 都被赋同一个 advantage。
Missing image: Pasted image 20260430171303.png
KL penalty 放在哪里
PPO 是 reward / advantage 级别 的 KL 惩罚;GRPO 是 policy model vs reference model 级别 的单独约束。
在 PPO 里,KL penalty 通常先被加进 token-level reward:
再会进入 GAE,最后影响 。也就是说,PPO 的 KL 是先改变 reward,再通过 advantage 间接影响 policy update。
GRPO 的处理更干净:advantage 只来自组内 reward 的相对高低,KL 不混进 ,而是作为单独的 regularization term 直接放进 loss:
这里的 控制 KL 约束强度: 越大,policy 越不敢偏离 reference model; 越小,policy 更新空间越大,但也更容易跑偏。这篇 DeepSeekMath-RL 训练里用的 KL 系数 是 0.04。
这样做可以避免 KL penalty 把 advantage 的计算搞复杂,尤其适合 GRPO 这种本来就想用组内相对 reward 来替代 critic 的设计。
Towards to a Unified Paradigm
论文后面把 SFT、RFT、DPO、PPO、GRPO 放到一个统一视角里看:这些方法本质上都在决定 哪些 token 应该被提高概率、哪些 token 应该被降低概率,以及力度有多大。
统一写法大概是:
这里最核心的是两部分:
表示:如果我要提高当前 token 的概率,参数应该往哪个方向动。
表示:算法 给这个 token 的更新系数,也就是这一步应该多强地强化或惩罚。
直觉上:
| 含义 | |
|---|---|
| 提高这个 token 的概率 | |
| 降低这个 token 的概率 | |
| 不更新这个 token | |
| 绝对值越大 | 更新力度越强 |
所以这条公式可以读成:
先看当前 token 的 log-prob 梯度方向,再乘上该算法定义的 gradient coefficient。然后对一个回答里的所有 token 求平均,再对数据分布 取期望,得到这个训练方法的总体更新方向。
这个统一范式里有三个关键组件:
| 组件 | 作用 |
|---|---|
| Data Source | 训练样本从哪里来,比如人工 SFT 数据、SFT model 采样、当前 policy 在线采样 |
| Reward Function | 奖励信号从哪里来,比如规则判断、reward model、preference signal |
| Algorithm / | 怎么把 reward signal 转成 token-level 的更新系数 |
这样看,SFT / RFT / PPO / GRPO 的差别是:
- 数据从哪里来?
- reward / 监督信号是谁给的?
- 每个 token 的 gradient coefficient 怎么算?
几种方法:
| 方法 | 数据来源 | 监督 / reward 信号 | 更新方式 |
|---|---|---|---|
| SFT | 人工筛选好的 instruction tuning 数据 | 无额外 reward,默认示范答案是好的 | 所有 token 都按 学 |
| RFT | 对 SFT 题目,用 SFT model 采样回答 | Rule:按最终答案对错过滤 | 只保留正确回答继续 SFT |
| DPO | 对 SFT 题目,用 SFT model 采样成对回答 | Rule / preference:区分 preferred 和 rejected | 用 pair-wise DPO loss 拉开好坏回答概率 |
| Online RFT | 对 SFT 题目,用当前 policy 实时采样回答 | Rule:按最终答案对错过滤 | 在线保留正确回答继续训练当前 policy |
| PPO / GRPO | 对 SFT 题目,用当前 policy 实时采样回答 | Reward model 打分 | 根据 reward 转成 gradient coefficient,强化好回答、惩罚差回答 |
Missing image: Pasted image 20260430192820.png
Missing image: Pasted image 20260430192717.png