为什么读
这篇直接把 RLVR 的有效性拆到 token entropy 视角:不是所有 CoT token 都同等重要,高熵少数 token 像 reasoning path 的分叉点。它比单纯说”RL 让模型会推理”更具体,适合接在 DeepSeek-R1 / DeepSeekMath 后面读。
一句话
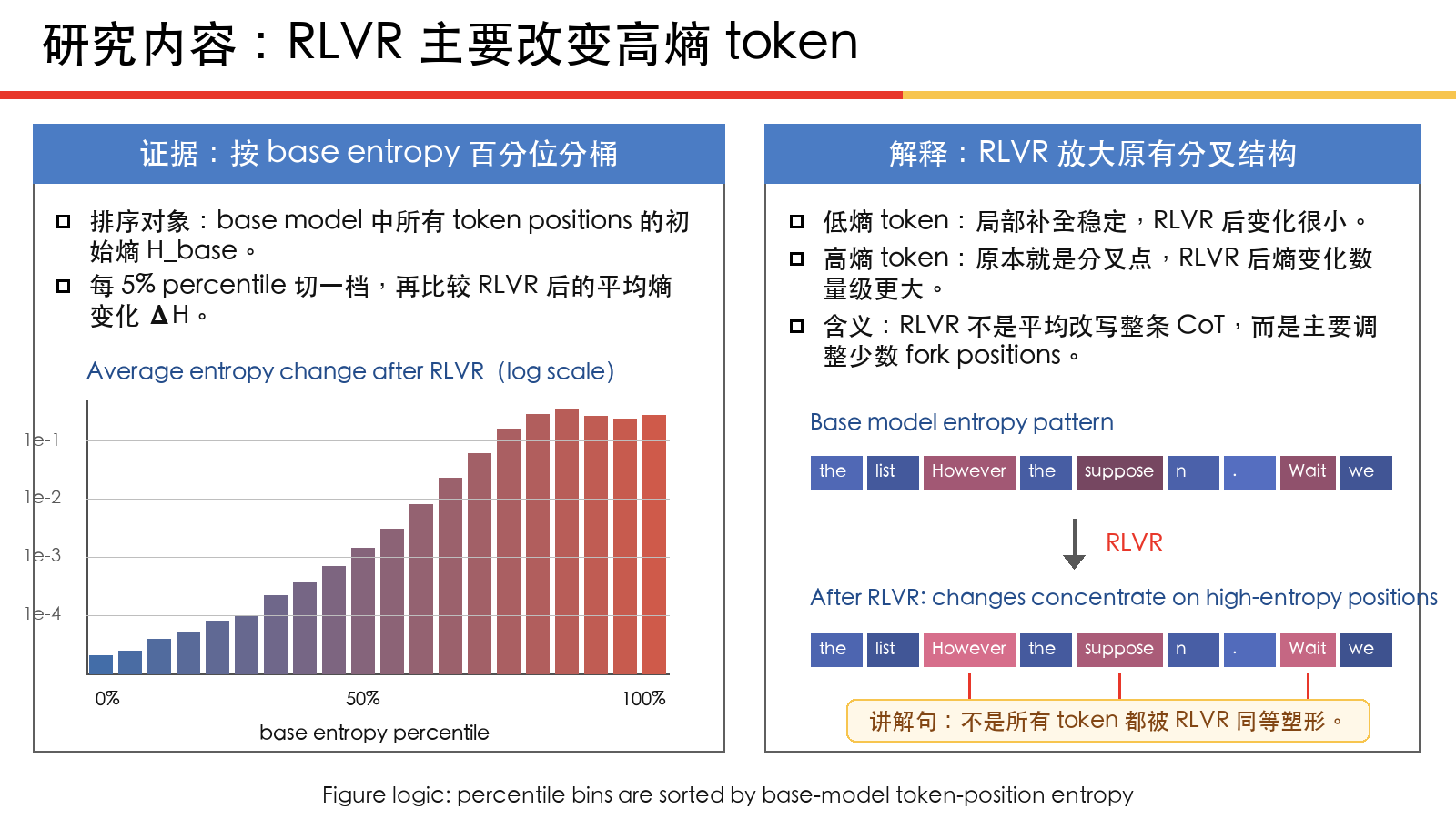
RLVR 主要优化的是高熵的”分叉 token”,而不是平均地改写整条推理链。
Token entropy 怎么算
论文里的 token entropy 指的是:在生成第 个 token 之前,模型面对整个词表的概率分布有多分散。
其中:
- 是词表大小。
- 是在第 个位置,模型给词表中第 个 token 的概率。
- ,意思是概率分布由当前题目 、已生成前缀 、logits 和 temperature 决定。
单个候选 token 对熵的贡献是 。它在 和 附近都接近 0,在 附近最大。直觉是:概率极低的 token 几乎不影响选择;概率极高的 token 也没有分叉;真正制造不确定性的,是那些概率不低、但又没有压倒性胜出的候选。****
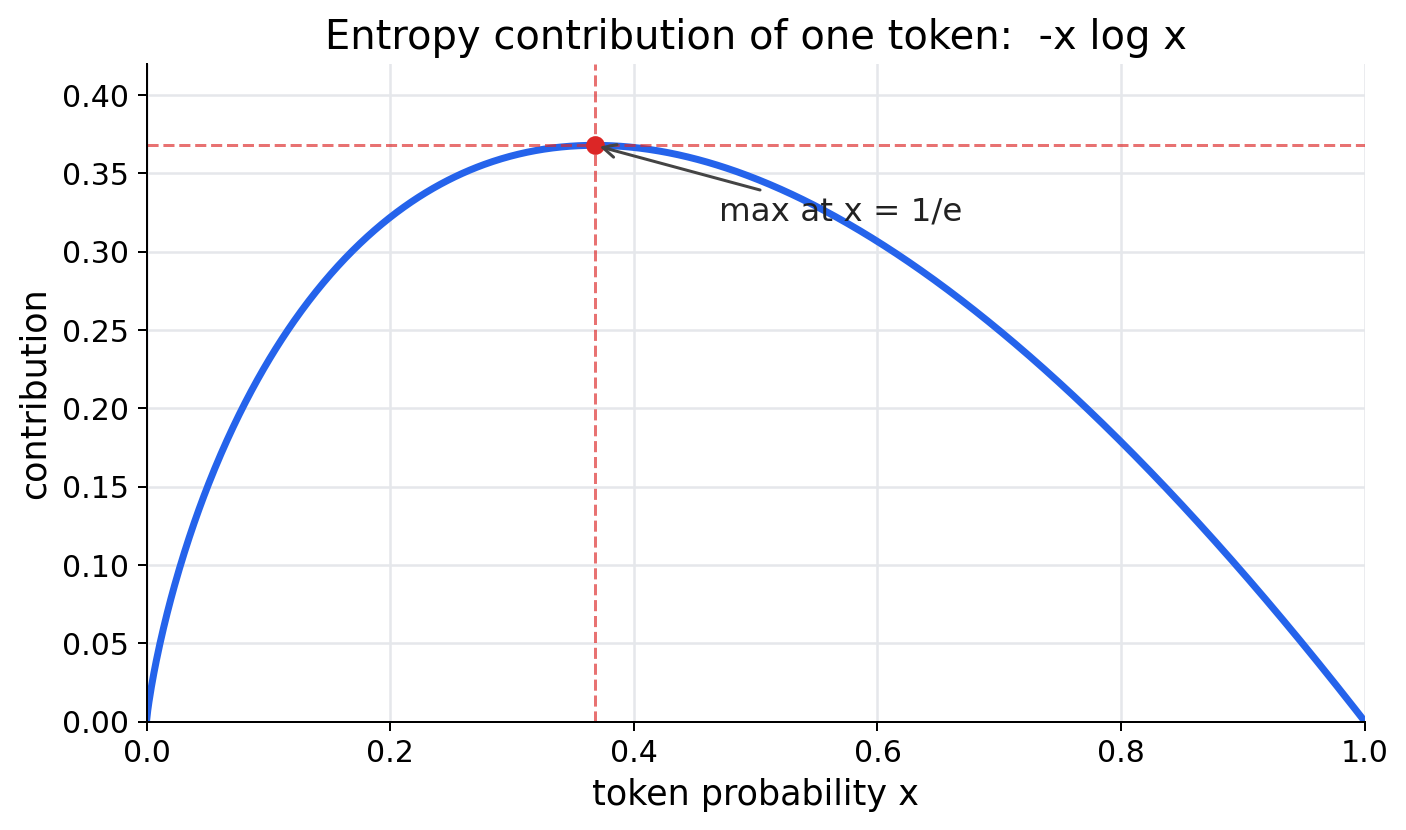
所以一条 response 里说 top 20% high-entropy tokens,指的是先对这条生成序列里的每个 token 位置算一个 ,再按 从高到低排序,取前 20% 的位置。这里的 token 更准确说是 token position,不是词表里的固定 token 类型。
论文观察到的三个 entropy 现象
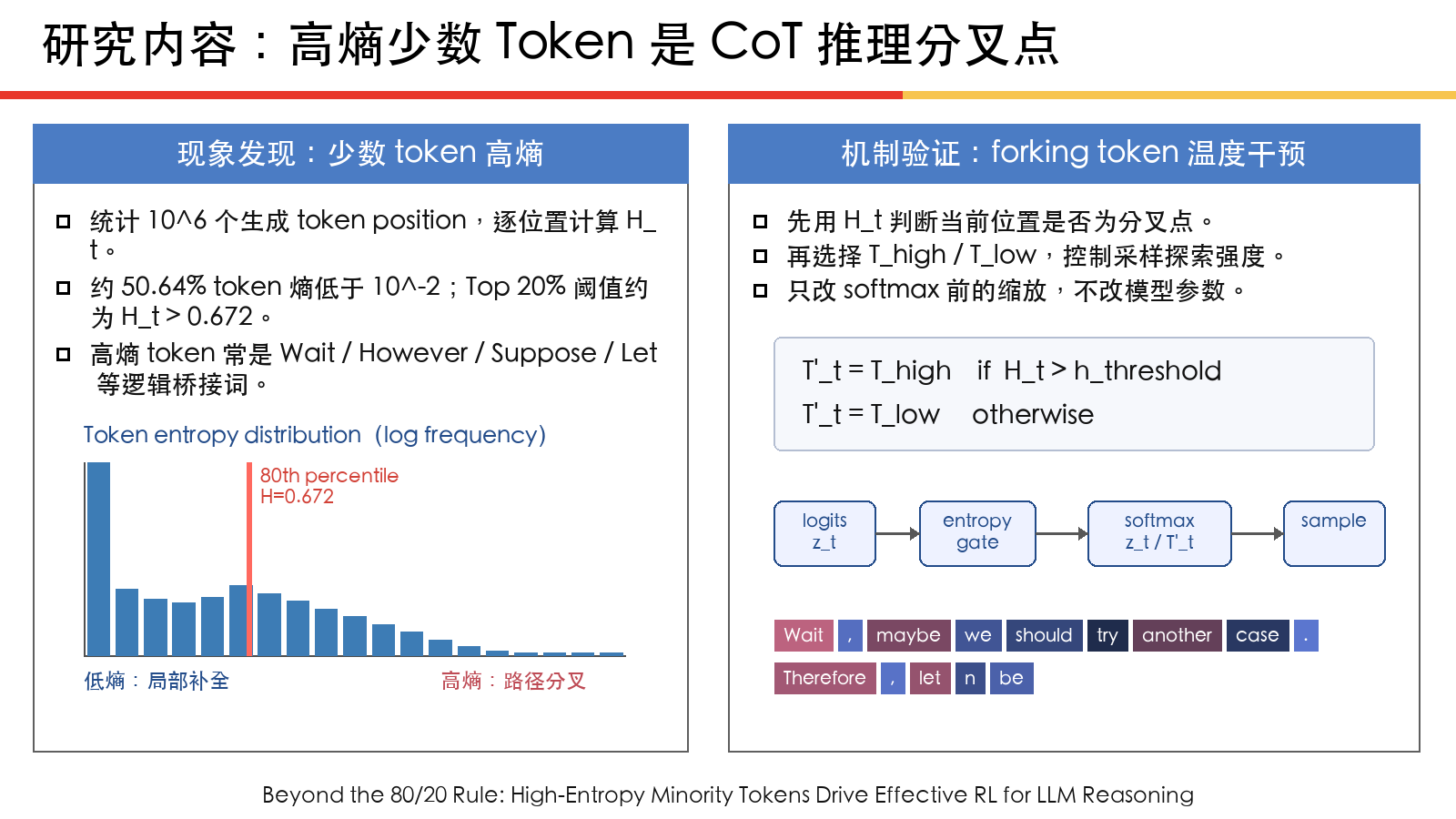
现象 1:CoT 里只有少数 token 是高熵的。 论文观察到,大量 token 的生成熵很低,超过一半 token 的 entropy 低于 ,而只有约 20% token 的 entropy 大于 0.672。这说明推理链不是每一步都在真正分叉,大部分 token 只是顺着已经确定的局部结构往下写;真正不确定、会影响路径选择的位置只占少数。
现象 2:高熵 token 往往负责连接两个连续推理片段,低熵 token 往往负责补完当前句子或单词。 高熵 token 常见于逻辑转折、递进、因果、条件和定义入口,比如 wait、however、unless、thus、also、since、because,以及数学推导里的 suppose、assume、given、define。低熵 token 则更常是词缀、代码片段、数学表达式组件这类确定性很高的位置。也就是说,高熵不是”这个词稀有”,而是”这个位置承担了从一个 reasoning segment 跳到另一个 segment 的桥接功能”。
现象 3:高熵 token 可以被视为 CoT 里的 forking tokens。 作者把这些高熵位置叫作 fork,因为它们对应推理过程里的多分支选择。为了验证 fork token 的作用,论文对 fork token 和其他 token 使用不同 temperature:
其中:
Temperature 介入的是 logits 到 probability 的 softmax 这一步: 不变,只是在 softmax 前除以 。 会放大 logit 差距,让分布更尖; 会压缩 logit 差距,让分布更平。这个干预本身不知道哪个 token “更对”,它只是改变采样时探索不同候选的强度。
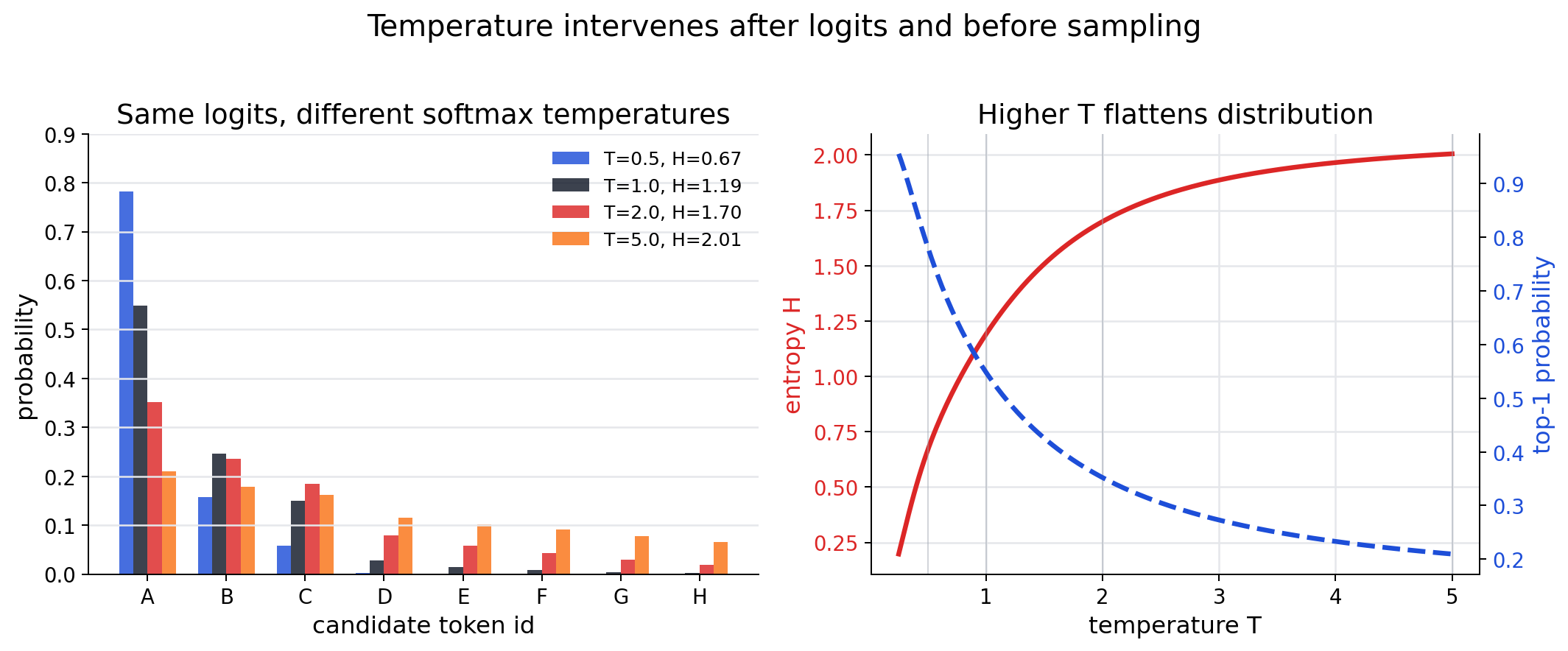
直觉是:如果 超过阈值,就把这个位置当成分叉点,用更高或单独设置的 temperature 控制它的探索;其他低熵位置则用较低 temperature,保持确定性。这个实验设计把”高熵 token 是推理分叉点”从描述性观察推进到可干预变量。
GRPO vs DAPO 公式对比
GRPO 的核心是:对同一个问题 采样 条回答 ,用组内 reward 做标准化 advantage,不再训练 value model。
token 级 importance ratio 是:
GRPO 目标函数:
DAPO 可以看成是在 GRPO 上做工程化修正,目标是让长 CoT RL 更稳定、更不容易 entropy collapse。它的主公式是:
同时 DAPO 加一个动态采样约束:
意思是:同一个问题采样出的 条回答不能全对,也不能全错。全对或全错时,组内 reward 没差异,advantage 接近 0,更新信号弱。
两者关键差异:
- GRPO 是 sample-level normalization:先对每条 response 内部 token loss 取平均,再对 条 response 平均。每条 response 权重差不多,长回答里的每个 token 被稀释。
- DAPO 是 token-level normalization:直接除以整个 group 的总 token 数 。每个 token 更接近等权,长 CoT 里的 token 不会因为 response 长而被过度稀释。
- GRPO 用对称 clip:,例如 。
- DAPO 用 clip-higher:,上界单独放宽,例如 。直觉是给低概率但有正 advantage 的探索 token 更多上升空间。
- GRPO 保留 KL penalty:公式里有 。
- DAPO 去掉 KL penalty:长 CoT reasoning RL 本来就希望模型明显偏离初始策略,过强 KL 会限制推理策略长出来。
和这篇 high-entropy token 论文的关系:DAPO 的 clip-higher 不直接识别”高熵 token”,但它放宽了正 advantage token 的上升上界;如果高熵 token 正好是 reasoning fork,并且某条 fork 得到正 reward,那么 clip-higher 会比 entropy bonus 更像”给关键分叉放行”,而不是全局鼓励模型变得更随机。
讲解参照图
重点段落
-
高熵 token 在 CoT 中承担 reasoning fork 的论证。
-
RLVR 训练前后 entropy pattern 的变化:base model 原有的不确定性结构是否被保留。
-
只对 top 20% 高熵 token 做 policy gradient update 的实验设计与 scaling trend。
读完要回答
-
作者所谓 high-entropy minority tokens 是机制发现,还是一种训练 trick?
-
这种 token-level fork 视角能不能迁移到 audio latent reasoning?如果不能,卡在 audio encoder / LLM backbone / decoder 哪一段?
-
如果 latent thoughts 不是显式 token,而是 hidden state,“高熵分叉点”应该怎么定义?