🧱 3. 语音基础表示
Waveform 是什么
语音的本质是空气振动,麦克风把它转换成随时间变化的电压信号。数字化之后,就是一串浮点数序列,这就是 waveform(波形)。
-
采样率 (sample rate) = 每秒采多少个点,常见 16 kHz(语音)或 22.05 / 24 kHz(TTS)。
-
1 秒 16 kHz 音频 = 16000 个数值点。
-
waveform 是 时域 (time-domain) 表示:横轴是时间,纵轴是振幅。
关键直觉:waveform 信息完整,但对模型来说”太原始”——每个采样点粒度极细,信号里频率信息是隐式的,不好直接学。
Spectrogram 和 Mel Spectrogram
Spectrogram(频谱图)
Important
FFT(Fast Fourier Transform,快速傅里叶变换)
对一整段信号做频率分解——告诉你”这段信号里总共有哪些频率”,但丢失时间信息。
输入:一段时域信号 → 输出:各频率分量的幅度与相位(1D)
Important
STFT(Short-Time Fourier Transform,短时傅里叶变换)
FFT 的带时间轴版本:用滑动窗口把波形切成小段,逐段做 FFT,再按时间拼起来。
输入:波形 + 窗口参数 → 输出:2D 时频矩阵(spectrogram)
STFT = 滑动窗口 + 逐窗 FFT
对 waveform 做 STFT(短时傅里叶变换),就得到 spectrogram。
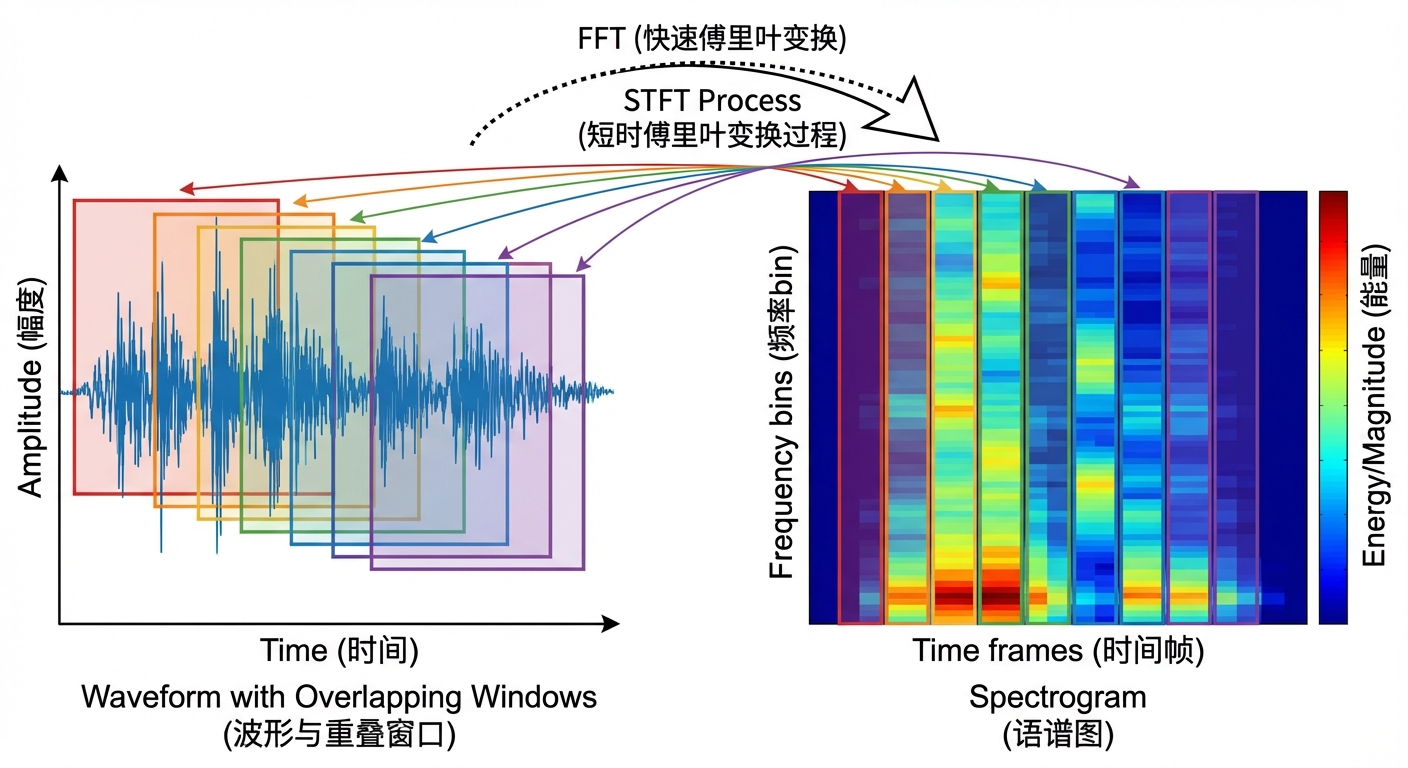
Waveform → STFT → Spectrogram 示意图
-
把波形切成一段段重叠的小窗口(frame),对每个窗口做 FFT。
-
结果是一个 2D 矩阵:横轴 = 时间帧 (frames),纵轴 = 频率 bin,值 = 该时刻该频率的能量(通常取对数)。
-
这就把时域信号变成了 时频表示 (time-frequency representation)。
-
🔬 STFT 详解(Step 0~5)
-
Step 0:你手上有什么
一段离散音频信号 ,共 个采样点。比如 1 秒 16kHz 音频 → 。
-
Step 1:选窗函数(Window Function)
你需要一个”窗”来截取信号片段。硬切(矩形窗)会在边界产生 频谱泄漏——突然截断引入虚假高频分量。
关键参数:窗长 (
win_length),常见 4002048 个采样点(25ms128ms @ 16kHz)。常用窗函数:
-
Hann 窗(最常用): w共L个点
-
Hamming 窗:类似 Hann,但边缘不完全到零
-
矩形窗:(最简单,泄漏最严重)
窗的作用:让截取片段两端平滑衰减到零,减少频谱泄漏。
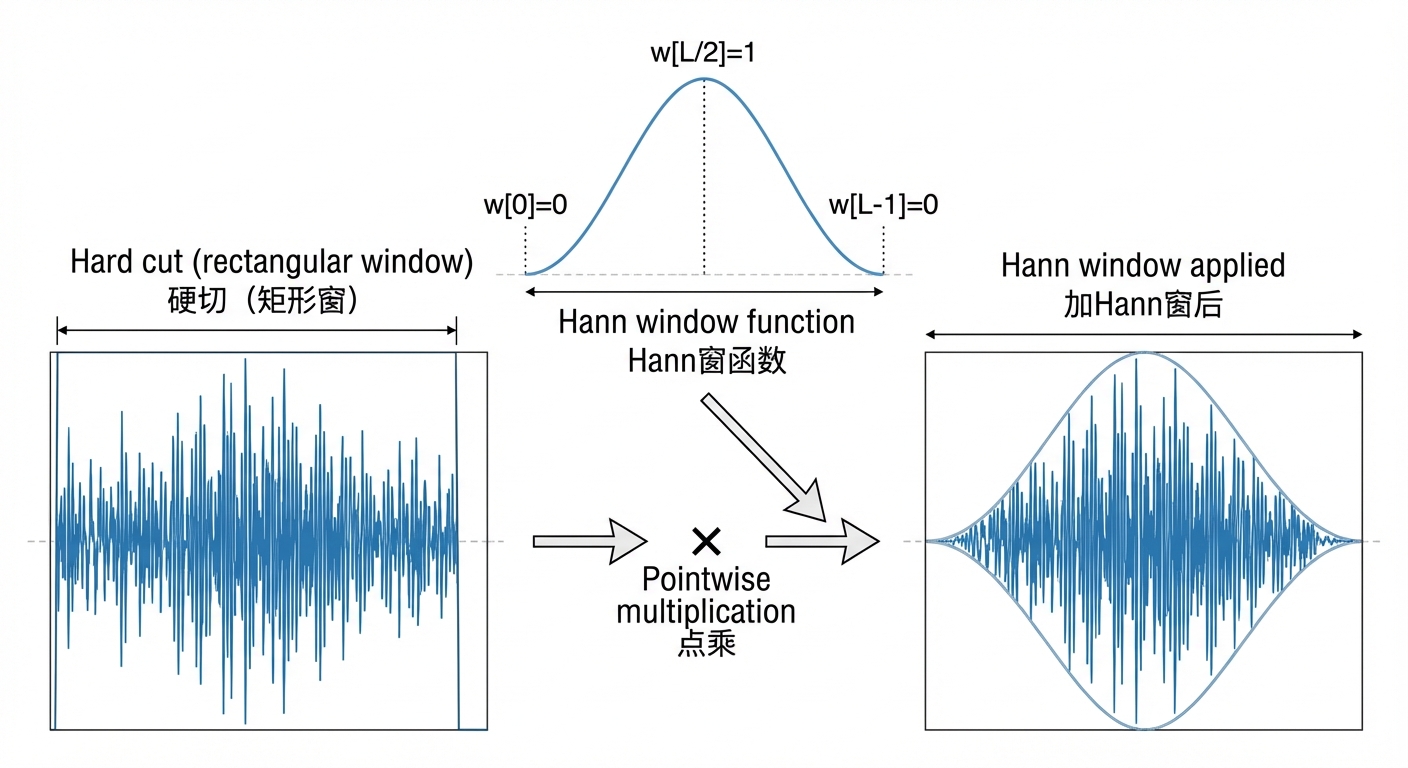
Hann 窗函数淡入淡出示意图
为什么乘上窗就能”平滑衰减”? 以 Hann 窗为例,代入两端和中间:
-
左端 :
-
中间 :
-
右端 :
整体形状是一个钟形曲线:两端为 0,中间为 1,过渡是平滑余弦。原始信号x[n]乘以 后,两端被压到零、中间完全保留、过渡区逐渐放大/缩小——就像给信号加了”淡入淡出”效果。
如果不加窗(硬切),边缘突变 → FFT 误判为高频 → 频谱泄漏。平滑到零就消除了这个假象。
-
-
Step 2:滑动窗口切片(Framing)
三个参数决定怎么切:
-
win_length:每个窗口的长度(采样点数),典型 400(25ms @ 16kHz) -
hop_length:相邻窗口起点间隔,典型 160(10ms) -
overlap:重叠部分 = win_length − hop_length,典型 240(15ms)
具体操作:
-
第 0 帧:取
-
第 1 帧:取 ( = hop_length)
-
第 帧:取
-
总帧数 ≈
为什么要重叠? 窗函数把两端压到零,不重叠会丢信号。重叠 50%~75% 保证每个采样点都被充分覆盖。
-
-
Step 3:加窗(Windowing)
对第 帧的信号逐点乘上窗函数:
这一步把截取片段”修整”成两端平滑衰减的形状。
-
Step 4:做 FFT(核心变换)
对每个加窗片段 做 点 DFT(通常 或补零到 2 的幂):
输出 是复数:
-
幅度 → 该频率的能量强度
-
相位 → 该频率的相位信息
实数信号对称,只需保留前 个频率 bin。
-
-
Step 5:取幅度谱 → Spectrogram
(功率谱),或取对数:
加 防止 log(0)。
最终矩阵形状:(频率 bins, 时间帧) =
-
Mel Spectrogram
人耳对频率的感知不是线性的——低频区分辨率高,高频区分辨率低。Mel 标度 模拟了这种非线性。
-
在 spectrogram 的线性频率轴上套一组 mel 滤波器组 (mel filter bank),把几百个频率 bin 压缩到几十个 mel bin。
-
常见设置:80 mel bins(也有 64 或 128)。
-
再取 log → 得到 log-mel spectrogram,这就是模型最常用的输入/输出格式。
mel_bins、frames、hop_length 的关系
三个量各管一个维度:
| 概念 | 决定什么 | 典型值 |
|---|---|---|
mel_bins | 频率轴的分辨率(有多少条 mel 通道) | 80 |
frames | 时间轴有多少帧 | 取决于音频长度和 hop_length |
hop_length | 相邻帧之间滑动多少个采样点 | 256(≈ 16ms @ 16kHz) |
关键公式:
举个例子:
-
1 秒 16 kHz 音频 → 16000 个采样点
-
hop_length = 256→ 帧 -
最终 mel spectrogram 形状:
(mel_bins, frames)=(80, 63)
直觉:
hop_length越小 → 帧越多 → 时间分辨率越高(但计算量也越大)。
为什么模型预测 mel,不直接预测 waveform?
这是最核心的问题,理由有三层:
① 维度灾难
-
1 秒波形 = 16000~24000 个点,10 秒就是 24 万点。
-
1 秒 mel = ~63 帧 × 80 bins ≈ 5000 个值。
-
mel 比 waveform 压缩了约 3~5 倍,序列长度更是缩短了几百倍(从 16000 → 63)。自回归/扩散模型处理短序列效率天差地别。
② 结构化信息更显式
-
mel 把频率结构”摊开”了——基频、共振峰、噪声带都在不同 mel bin 上清晰可见。
-
waveform 是一维振荡,这些信息全部折叠在一起,模型要自己学”傅里叶变换”,负担极大。
③ 分工解耦
-
语言/韵律/内容 → 用 acoustic model 映射到 mel(语义层面)。
-
相位恢复 + 高频细节 → 交给专门的 vocoder(信号层面)。
-
这种拆分让每一步都更简单、更好训练。
一句话总结:mel 是语音的”中间画布”——足够紧凑让生成模型好学,又足够丰富让 vocoder 能还原出高质量波形。
🔊 6. Vocoder
Important
一句话分工:
Acoustic model 负责”生成 mel”,Vocoder 负责”把 mel 渲染成波形”。
Vocoder 是什么?
Vocoder(voice + coder)原本是上世纪的语音编码器,现在在 TTS 领域专指:把 mel spectrogram 转换成可播放的音频波形的模型。
它的输入输出非常明确:
-
输入:mel spectrogram,形状
(80, T)(T = 时间帧数) -
输出:waveform,形状
(T × hop_length,)(比 mel 长几百倍)
比如 mel 有 63 帧,hop_length=256 → 输出 63×256 = 16128 个采样点 ≈ 1 秒音频。
类比:mel 像一张“乐谱”,vocoder 就是“演奏家”——看着谱把声音弹出来。
为什么需要单独的 vocoder?
是什么?— 把 mel 频谱解码成波形的模块
你可能会想:mel 不就是从 waveform 算出来的吗,反过来算回去不就行了?
不行。 原因是 STFT 过程中丢了东西:
-
① 相位信息丢失
STFT 输出是复数 ,包含幅度和相位。但 mel spectrogram 只保留了 幅度(能量),相位完全丢掉了。
相位决定了不同频率分量之间的时间对齐关系。没有相位,你知道“有 100Hz 和 300Hz”,但不知道它们的波峰怎么对齐——直接复原的波形会失真。
类比:你知道一幅画用了哪些颜色、各多少,但不知道每个像素是什么颜色——你没法复原这幅画。
-
② Mel 滤波器的信息压缩
Mel 滤波器把 257 个频率 bin 压缩到 80 个 mel bin,这是个 多对一 的映射,不可逆。
多个频率 bin 被加权求和成 1 个 mel bin 后,你无法知道原来每个频率 bin 各自贡献了多少。
类比:把 5 个数加起来得到 10,你无法反推这 5 个数分别是什么。
-
③ 从低分辨率到高分辨率
Mel 是时间上的低分辨率表示(每帧 ~10ms),而 waveform 是每个采样点(~0.06ms @ 16kHz)。
Vocoder 需要从 1 帧 mel “绘制”出 256 个采样点,这是一个巨大的 上采样 (upsampling) 问题。
所以 vocoder 不是简单的数学反运算,而是一个需要学习的 生成模型——它要学会”合理地补全丢失的信息”。
Vocoder 的演进历史
-
🟢 Griffin-Lim(经典算法,无神经网络)
用迭代算法从幅度谱估计相位,再做逆 STFT 还原波形。
-
优点:不需要训练,纯数学方法
-
缺点:音质差,有明显的金属声/水下声感,因为相位估计不准
-
地位:早期 baseline,现在已不用
-
-
🟡 WaveNet(2016,DeepMind)—— 第一个神经网络 vocoder
核心思想:自回归生成,逐个采样点预测。
每次生成 1 个采样点,条件是之前所有点 + mel 特征。
-
架构:因果卷积(causal dilated convolution)堆叠
-
音质:革命性突破,接近人声
-
致命缺点:极慢。生成 1 秒 16kHz 音频需要逐个预测 16000 次,实时率只有 ~0.1x
-
地位:证明了神经网络 vocoder 的可行性,但太慢不实用
-
-
🟠 WaveRNN(2018)—— 轻量化自回归
用单层 RNN 替代 WaveNet 的深层卷积,通过各种优化技巧(分组量化、稀疏矩阵)加速。
- 速度提升 ~4x,但仍然是自回归,本质上还是逐点生成
-
🟢 WaveGlow(2018,NVIDIA)—— 基于 Flow 的并行生成
核心突破:不再逐点生成,而是一次性并行输出整段波形。
基于 normalizing flow:把高斯噪声通过可逆变换映射到波形。
-
优点:并行推理,速度快很多
-
缺点:模型巨大(~268M 参数),显存消耗高
-
-
🔵 HiFi-GAN(2020)—— GAN 路线的王者 ⭐
现在最广泛使用的 vocoder 架构之一。
核心思想:用 GAN 训练一个生成器,让判别器区分不出生成音频和真实音频。
生成器架构:
-
输入 mel
(80, T)→ 通过多层 转置卷积 (transposed convolution) 逐步上采样 -
每次上采样后接 Multi-Receptive Field Fusion (MRF) 模块:多个不同 kernel size 的残差块并行处理再求和,捕捉不同尺度的波形模式
-
上采样倍率依次为 8×8×2×2 = 256 = hop_length,恰好把每帧 mel 拉伸到 256 个采样点
判别器(两个):
-
Multi-Period Discriminator (MPD):把波形按不同周期(2, 3, 5, 7, 11)reshape 成 2D,用 2D 卷积判别——捕捉周期性细节
-
Multi-Scale Discriminator (MSD):在原始波形、×2 下采样、×4 下采样上各跑一个 1D 卷积判别器——捕捉多尺度结构
损失函数:
-
GAN 对抗损失(让生成音频骗过判别器)
-
Mel reconstruction loss(生成波形再算 mel,和输入 mel 对比)
-
Feature matching loss(判别器中间层特征对齐)
结果:音质接近 WaveNet,速度快 1000倍以上,实时率轻松达到 ~100x。
-
-
🟣 BigVGAN(2022,NVIDIA)—— HiFi-GAN 的强化版
在 HiFi-GAN 基础上的改进:
-
用 Anti-Aliased Multi-Period Representation (AMP) 替代原始上采样,减少混叠伪影
-
用 Snake activation(周期性激活函数)替代 LeakyReLU,更适合建模音频的周期性结构
-
模型更大(到 112M 参数),训练数据更多
-
泛化能力更强:对未见过的说话人、音乐、环境音都能较好处理
-
-
🔴 Diffusion-based vocoder(DiffWave, WaveGrad 等)
用扩散模型做 vocoder:从噪声出发,逐步去噪还原波形。
-
音质非常好,但需要多步迭代(通常 20~50 步)
-
比 HiFi-GAN 慢,但比 WaveNet 快
-
目前在生产环境用得较少,主要在研究中
👉 详见子页面:DiT- Scalable Diffusion Models with Transformers论文笔记
-
Vocoder 内部在做什么?(以 HiFi-GAN 为例)
拆解整个数据流:
输入: mel spectrogram (80, 63) ← 1秒音频
Step 1:初始卷积
(80, 63) → Conv1d → (512, 63)
把 80 个 mel 通道扩展到 512 个特征通道。
Step 2:逐步上采样(核心)
每次用转置卷积把时间轴拉长,同时减少通道数:
-
(512, 63)→ ×8 →(256, 504) -
(256, 504)→ ×8 →(128, 4032) -
(128, 4032)→ ×2 →(64, 8064) -
(64, 8064)→ ×2 →(32, 16128)
8 × 8 × 2 × 2 = 256 = hop_length ✅
每次上采样后都接 MRF 模块(多尺度残差卷积)细化波形细节。
Step 3:输出卷积
(32, 16128) → Conv1d → (1, 16128) → tanh
32 个通道压缩到 1 个通道 = 单声道波形。tanh 把值压到 [-1, 1]。
最终输出: 16128 个采样点 ≈ 1.008 秒音频 @ 16kHz ✅
本质:就是一个 全卷积的上采样网络,把低分辨率的 mel 一步步拉伸到高分辨率的波形。GAN 训练保证拉伸出来的细节是“真实”的。
TTS 全局视角:Vocoder 在哪里?
典型的现代 TTS pipeline:
Important
文本 → Text Encoder → 语言特征
→ Acoustic Model(如 FastSpeech2, VITS, Grad-TTS)→ Mel Spectrogram
→ Vocoder(如 HiFi-GAN)→ Waveform 🔊
Vocoder 是最后一环——前面所有模块的努力都汇聚成 mel,vocoder 负责“最后一公里”把它变成你能听到的声音。
注意:像 VITS 这样的 端到端模型 把 acoustic model 和 vocoder 融合在一起,不再显式分开,但内部仍然有类似的逻辑分工。
🧩 7. 音频离散表示 / VQ-VAE
Important
核心动机:mel 是连续的浮点矩阵,语言模型只能处理离散 token。VQ-VAE 的作用就是把连续音频压成一串整数序列,让 LLM 能像处理文字一样处理声音。
VQ-VAE 是什么?
VQ-VAE(Vector Quantized Variational Autoencoder)由 DeepMind 在 2017 年提出,核心思想:
-
Encoder:把输入(图像/音频)压成连续的隐向量
-
Vector Quantization(向量量化):把 映射到一个有限的 codebook 中最近的向量 ,输出离散 index
-
Decoder:从离散 index 重建原始输入
整个流程:输入 → Encoder → (连续)→ 查 codebook → (离散化)→ Decoder → 重建
类比:codebook 就像一本”声音词典”,有 N 个词条(向量),每帧音频被替换成词典里最像的那个词的编号。
Codebook 与量化
Codebook:一个可学习的矩阵,形状 , 是词典大小(如 512 或 1024), 是向量维度。
量化过程:
即找欧氏距离最近的 codebook entry,把 替换成 。
梯度问题:量化是 argmin,不可微。解决方案是 straight-through estimator:前向传播用量化值,反向传播直接把梯度从 穿过去传给 (假装没有量化这一步)。
用 stop-gradient 技巧可以把 STE 写成一个等式,让前向/反向行为自动分离:
-
前向: 内部的值参与计算,所以 (量化结果)
-
反向: 梯度为 0,所以 ,梯度原样穿透
损失函数:
-
codebook loss:把 codebook 向量往 encoder 输出拉
-
commitment loss:把 encoder 输出往 codebook 向量拉,防止 encoder 乱跳
-
= stop-gradient
RVQ(Residual Vector Quantization)
单层 VQ 表达能力有限——1 个 index 只能从 K 个向量里选 1 个。RVQ 用多层 VQ 叠加来提升精度:
-
第 1 层 VQ:量化 ,得到 index ,计算残差
-
第 2 层 VQ:量化残差 ,得到 ,计算新残差
-
以此类推,共 层
最终每帧音频用 个 index 表示,表达能力 = (远大于单层的 K)。
EnCodec(Meta)和 SoundStream(Google)都用了 RVQ,通常 4~8 层,每层 codebook 大小 1024,码率可按层数动态调整。
音频 Codec:VQ-VAE 的实际应用
现代神经音频 codec(如 EnCodec、SoundStream、DAC)的本质就是 VQ-VAE + RVQ,只是 encoder/decoder 换成了专为音频设计的卷积网络。
典型流程:
waveform → Conv Encoder → RVQ → 离散 token 序列(多层 index)→ RVQ Decoder → Conv Decoder → 重建 waveform
这些离散 token 就是语音大模型(VALL-E、Mini-Omni 等)里所说的 acoustic token——可以直接喂给 LLM 做自回归生成。
与 mel 路线的对比:
-
mel → vocoder:连续表示,音质好,但 LLM 不能直接建模
-
VQ-VAE codec tokens:离散表示,可以被 LLM 自回归生成,但音质受 codebook 大小限制
这正是为什么 VALL-E 用 EnCodec token,而 FastSpeech2 用 mel——取决于你要不要让 LLM 直接生成音频。
🎙️ 8. VAD 与语音唤醒
Important
核心区别:VAD 判断”有没有人在说话”,语音唤醒(Keyword Spotting / Wake Word Detection)判断”有没有说那个特定的词”。两者都是语音交互的入口守门员——不触发就不启动后续 ASR / TTS pipeline,直接关系到功耗和用户体验。
VAD(Voice Activity Detection)是什么?
语音活动检测,任务极简:逐帧判断当前音频是「语音」还是「非语音」(二分类)。
典型用途:
-
端点检测 (Endpointing):判断用户什么时候开始说话、什么时候说完,用来切分语音段送给 ASR
-
降低功耗:设备待机时只跑 VAD,检测到语音再唤醒大模型
-
降噪 / 会议转写:区分说话段和静音段,提升下游质量
经典方法:
-
能量阈值法:算每帧短时能量,超过阈值就判为语音。简单但对噪声不鲁棒。
-
WebRTC VAD:Google 开源的轻量 C 库,用 GMM 做帧级判断,延迟极低(10/20/30ms 帧),广泛用于实时通信。
-
Silero VAD:基于小型神经网络的 VAD,精度远超 WebRTC,模型仅 ~2MB,支持 PyTorch / ONNX,目前社区最常用的开源 VAD。
核心指标:
-
FRR (False Rejection Rate):把语音误判为静音 → 漏听
-
FAR (False Acceptance Rate):把噪声误判为语音 → 误触发
-
两者 trade-off,通过调阈值平衡
语音唤醒 / 关键词检测(Keyword Spotting)
唤醒词检测比 VAD 更进一步:不仅要检测”有声音”,还要识别特定关键词(如 “Hey Siri”、“小爱同学”)。
为什么不直接跑 ASR?
-
ASR 模型大、功耗高,不可能 7×24 在端侧运行
-
唤醒模型极轻量(几百 KB ~ 几 MB),可以常驻低功耗芯片,只有识别到唤醒词才启动主处理器 + ASR
典型架构演进:
-
🟢 DNN-KWS(Google, 2014)
最早的神经网络方案:对每帧 MFCC 特征用小型 DNN 做分类(关键词 / 非关键词 / 填充词)。
-
模型小(~100KB),适合嵌入式
-
但帧级分类缺乏时序建模能力
-
-
🟡 DS-CNN(Depthwise Separable CNN)
用深度可分离卷积大幅减少参数量,在 mel 特征图上做小模型分类。
-
ARM 提出的 keyword spotting 基准架构之一
-
精度和效率的平衡点很好,广泛用于 MCU 级部署
-
-
🔵 Attention-based 方案
在 CNN/RNN 基础上加 attention 聚合时间维度信息,提升对变长唤醒词的鲁棒性。
-
代表:Multi-Head Attention KWS
-
适合需要支持多个唤醒词的场景
-
-
🟣 端到端 + 自定义唤醒词
近年趋势:不再固定唤醒词,而是支持用户自定义。
-
方法:用 metric learning / 原型网络做 few-shot 关键词检测
-
用户只需录几遍自定义唤醒词,模型通过嵌入相似度判断是否匹配
-
VAD + 唤醒在语音交互系统中的位置
Important
麦克风常开 → VAD(有人说话吗?)→ KWS(说的是唤醒词吗?)→ ASR(说了什么?)→ NLU / LLM → TTS → 🔊
实际部署中的分层策略:
-
Stage 0(硬件级):超低功耗音频前端,持续采集
-
Stage 1(VAD):检测到语音活动才进入下一级,功耗 ~μW 级
-
Stage 2(KWS):确认唤醒词才启动主芯片,功耗 ~mW 级
-
Stage 3(ASR + 后续):主处理器全速运行,功耗 ~W 级
每一级都是漏斗——尽早过滤掉不需要处理的音频,节省算力和电量。这也是为什么智能音箱待机能撑几周的关键设计。